Search for and open Kinesis.
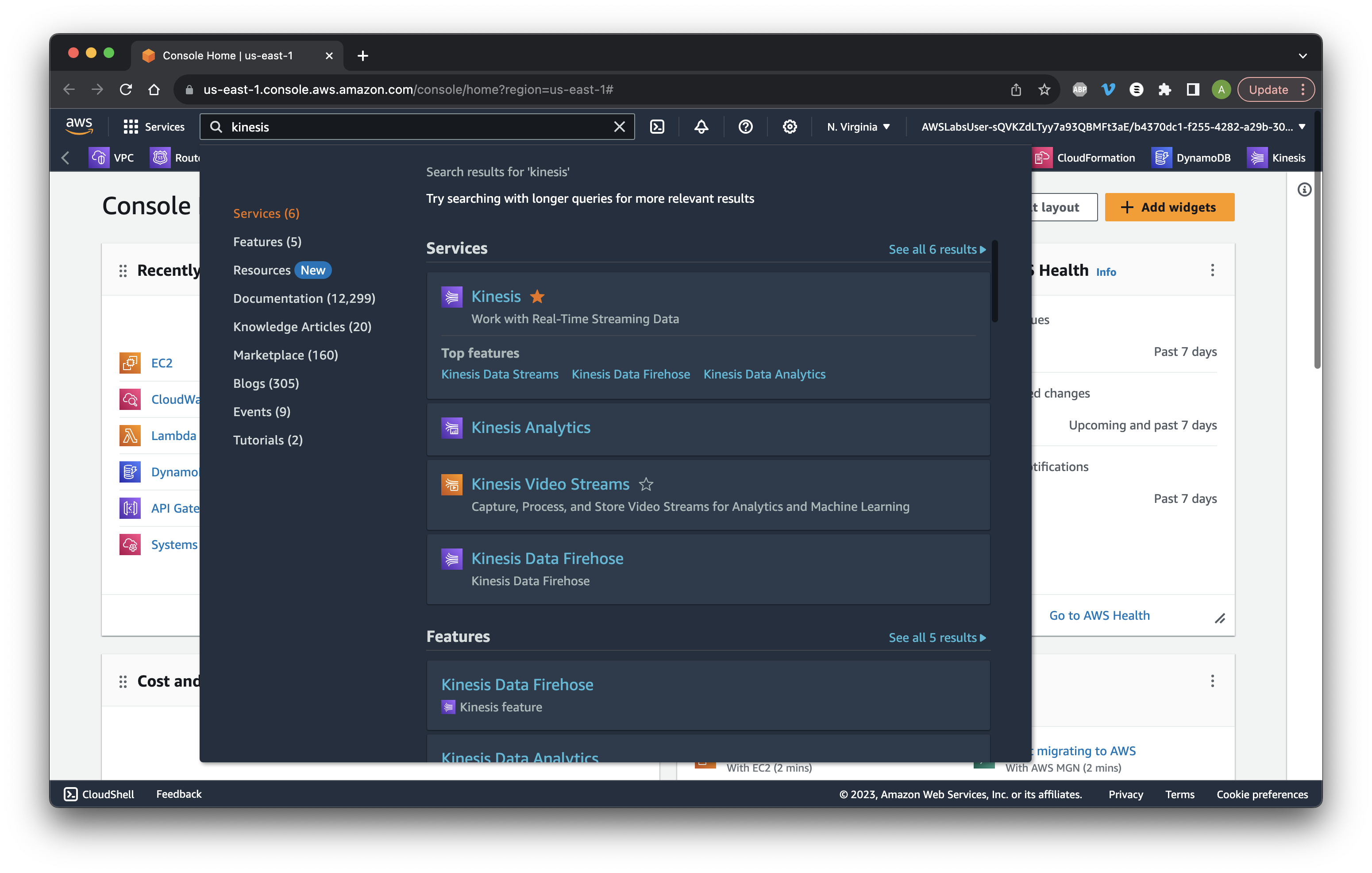
Search for and open Kinesis.
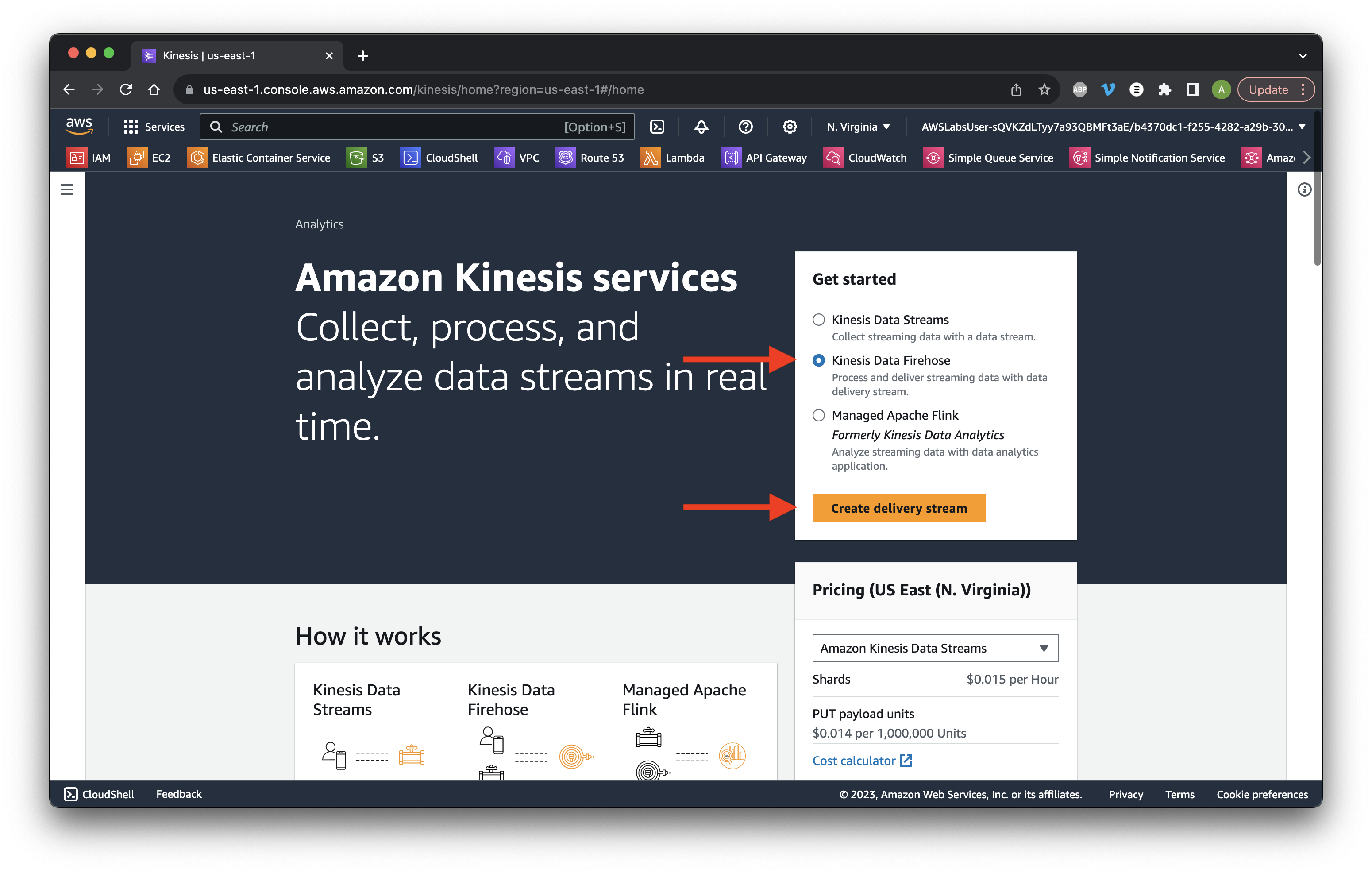
Choose KDF and click Create delivery stream.
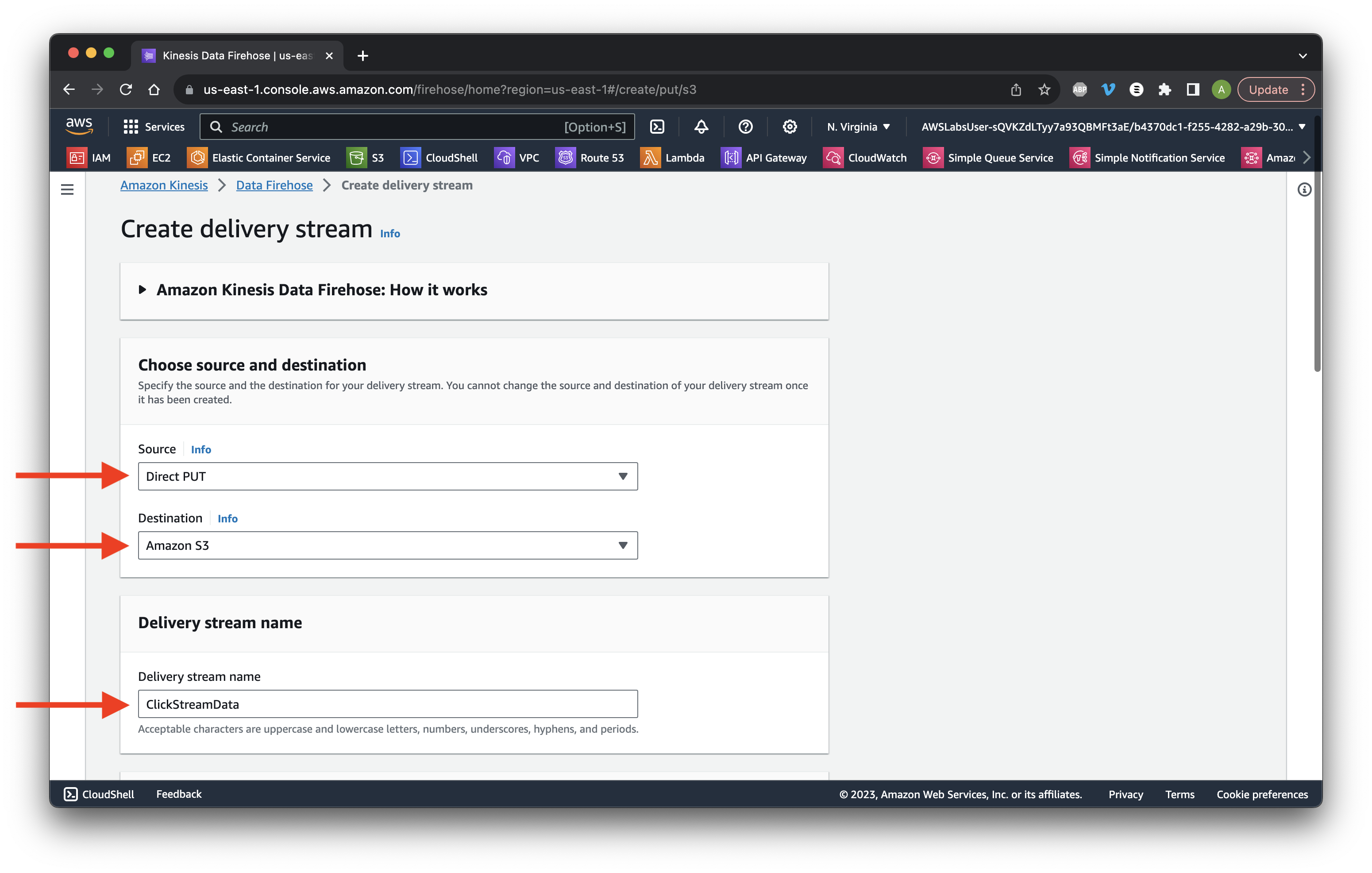
Choose Direct PUT to S3. Name the stream ClickStreamData.
Scroll down and select Enable data transformation. Click Browse Lambda functions.
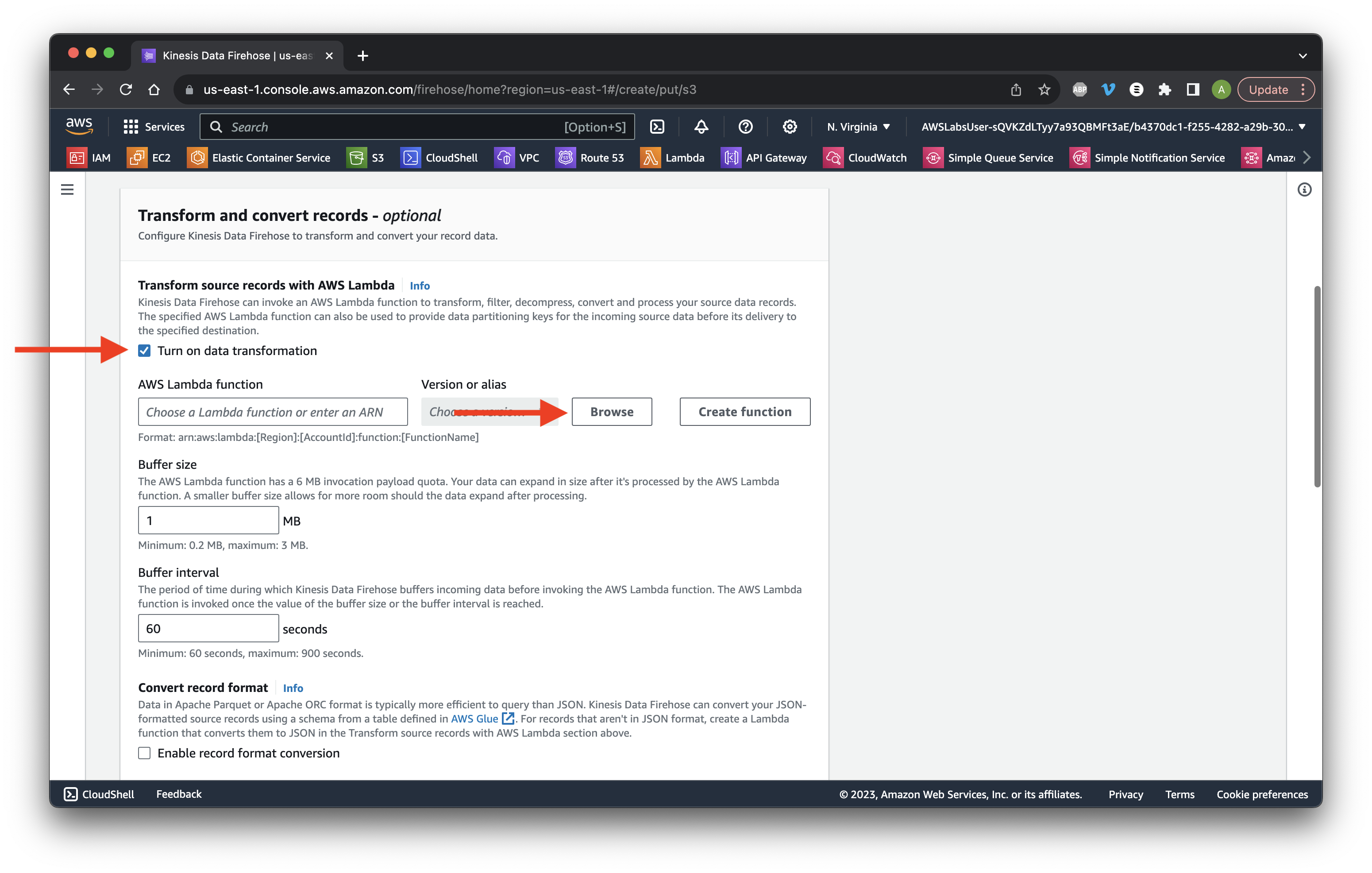
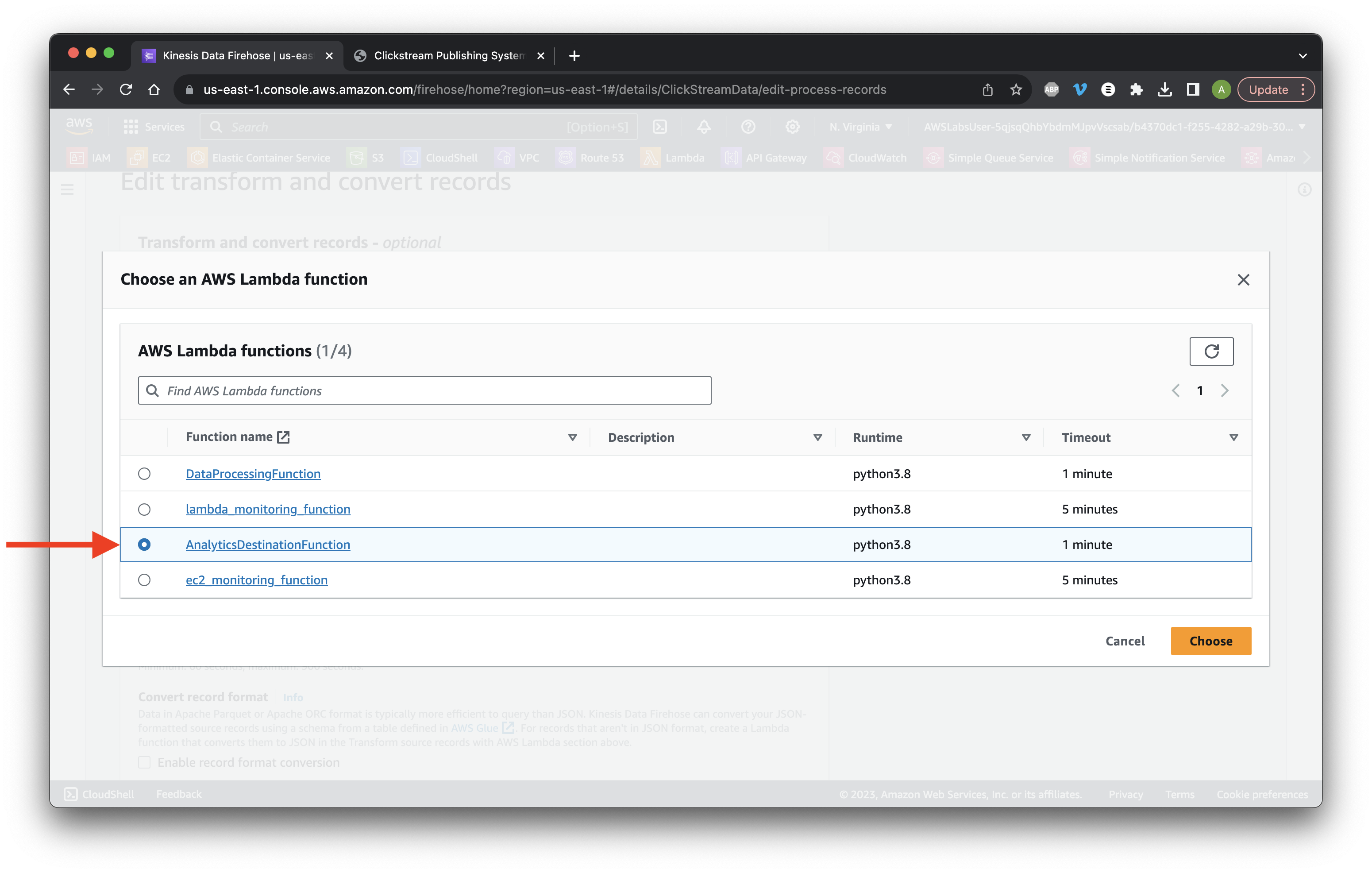
Select the DataProcessingFunction and click Choose.
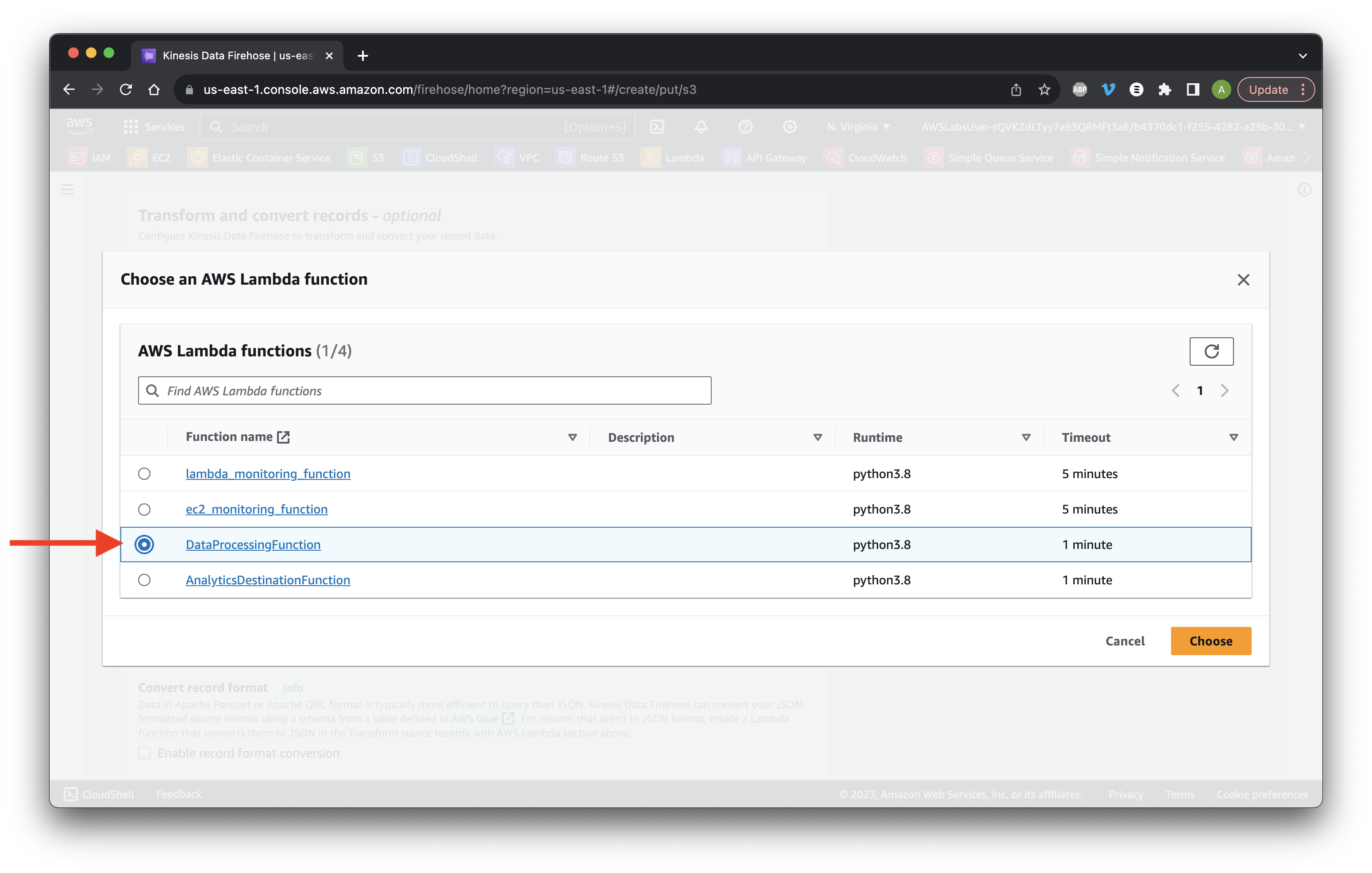
Scroll down and click Browse S3 buckets.
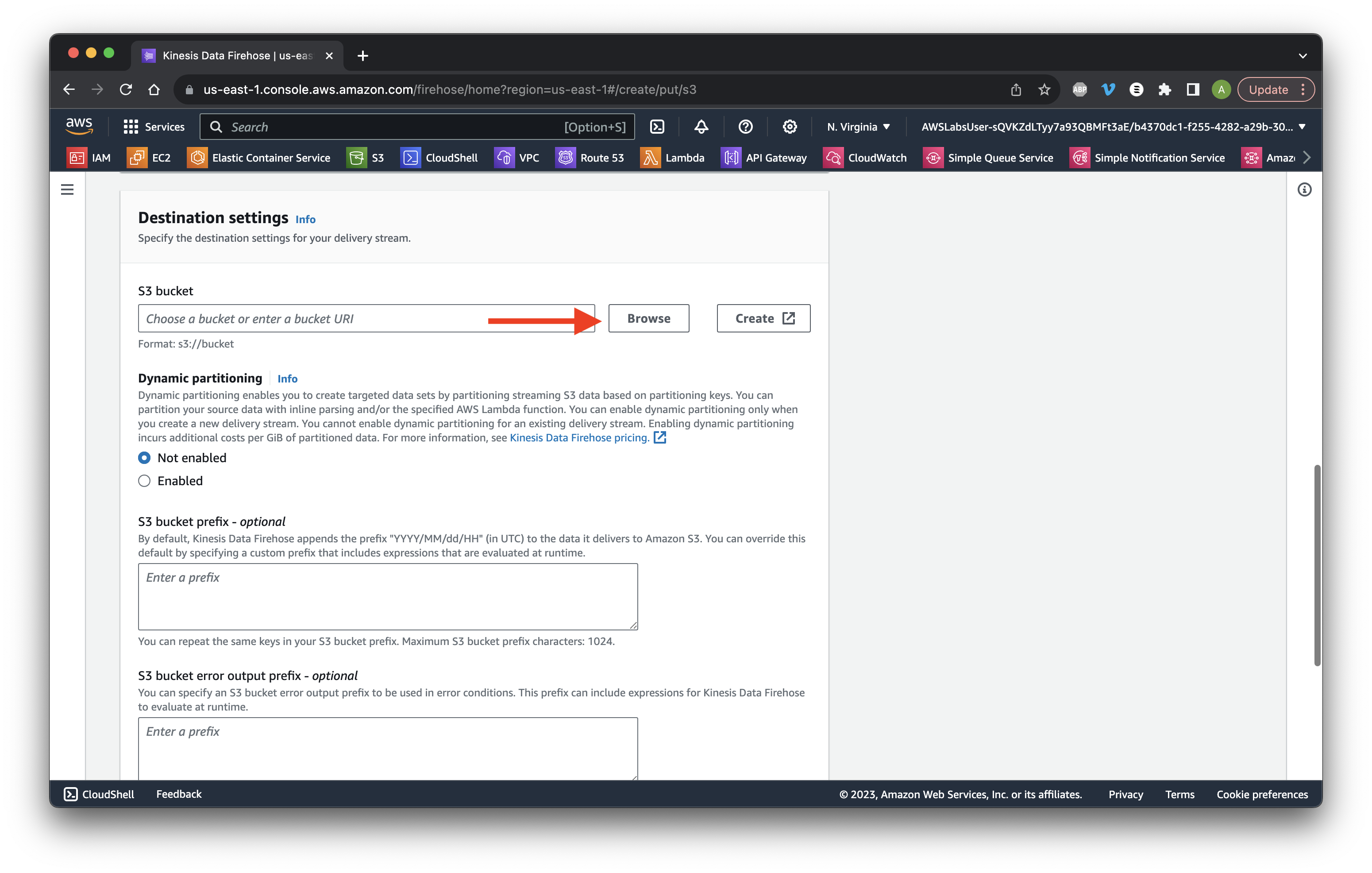
Select the data bucket and click Choose.
For the bucket prefix type processed_data/ and for error type error/.
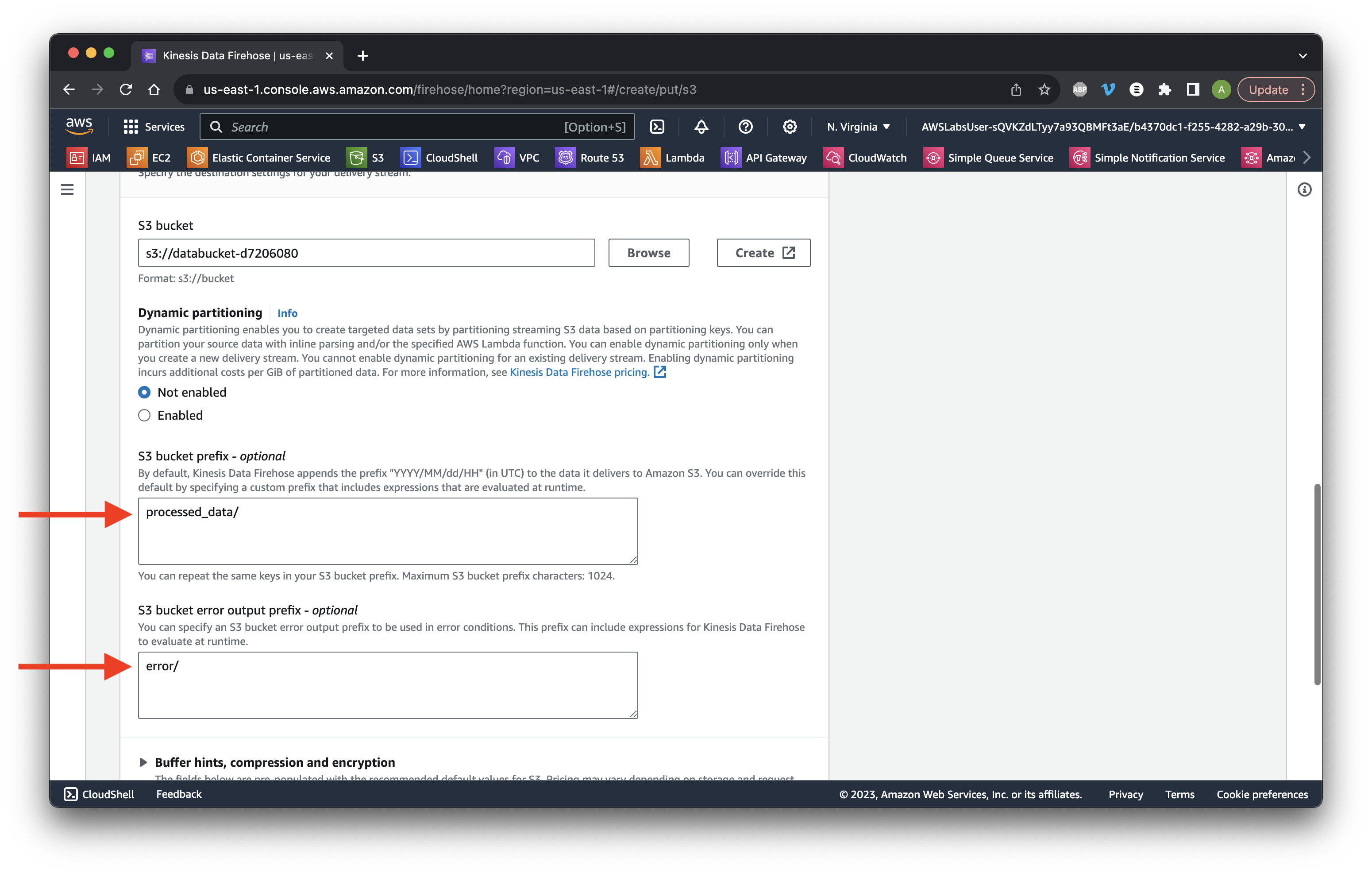
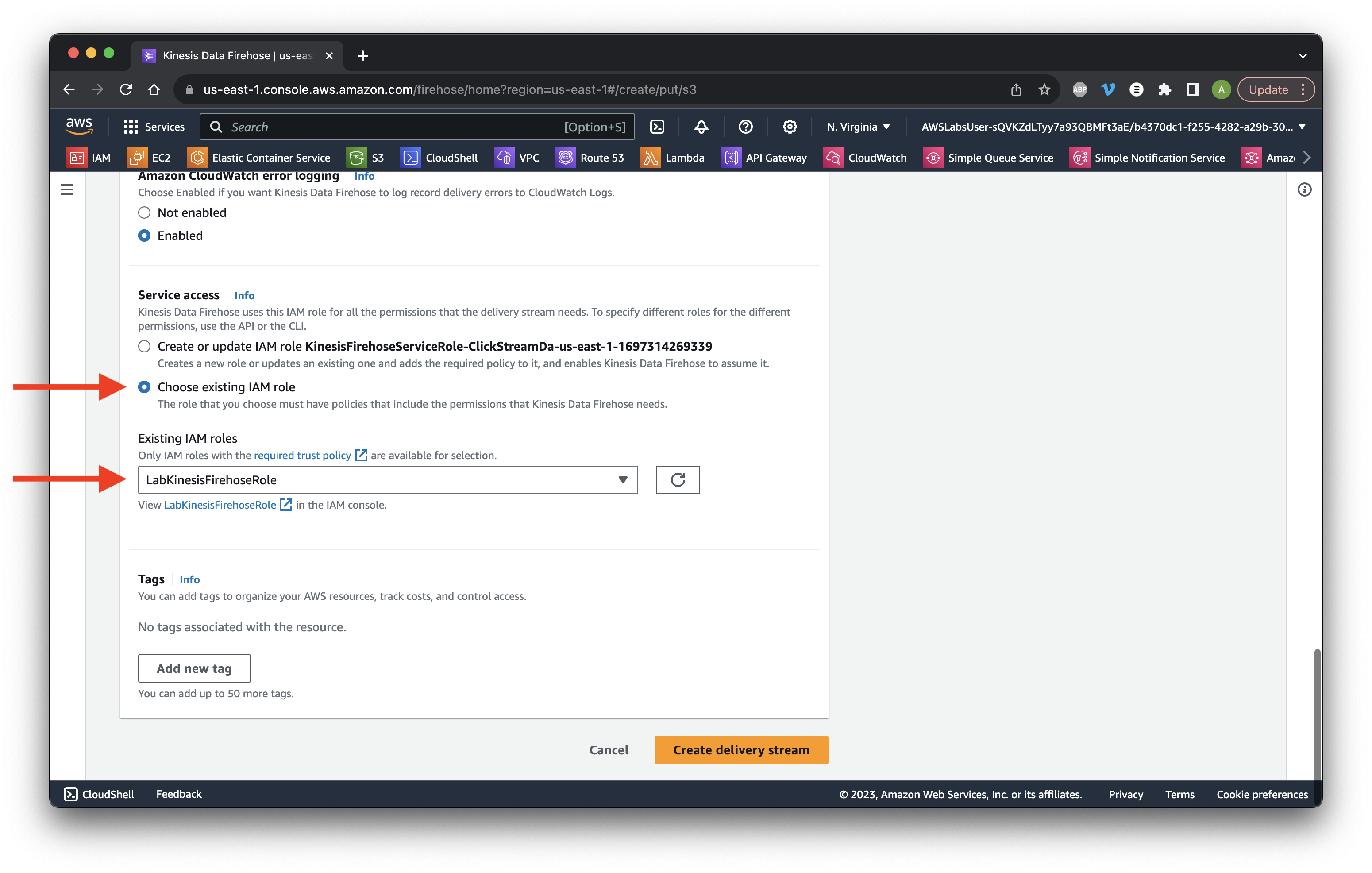
Go down to Advanced settings and Choose the existing IAM Lab role. Click Create delivery stream.
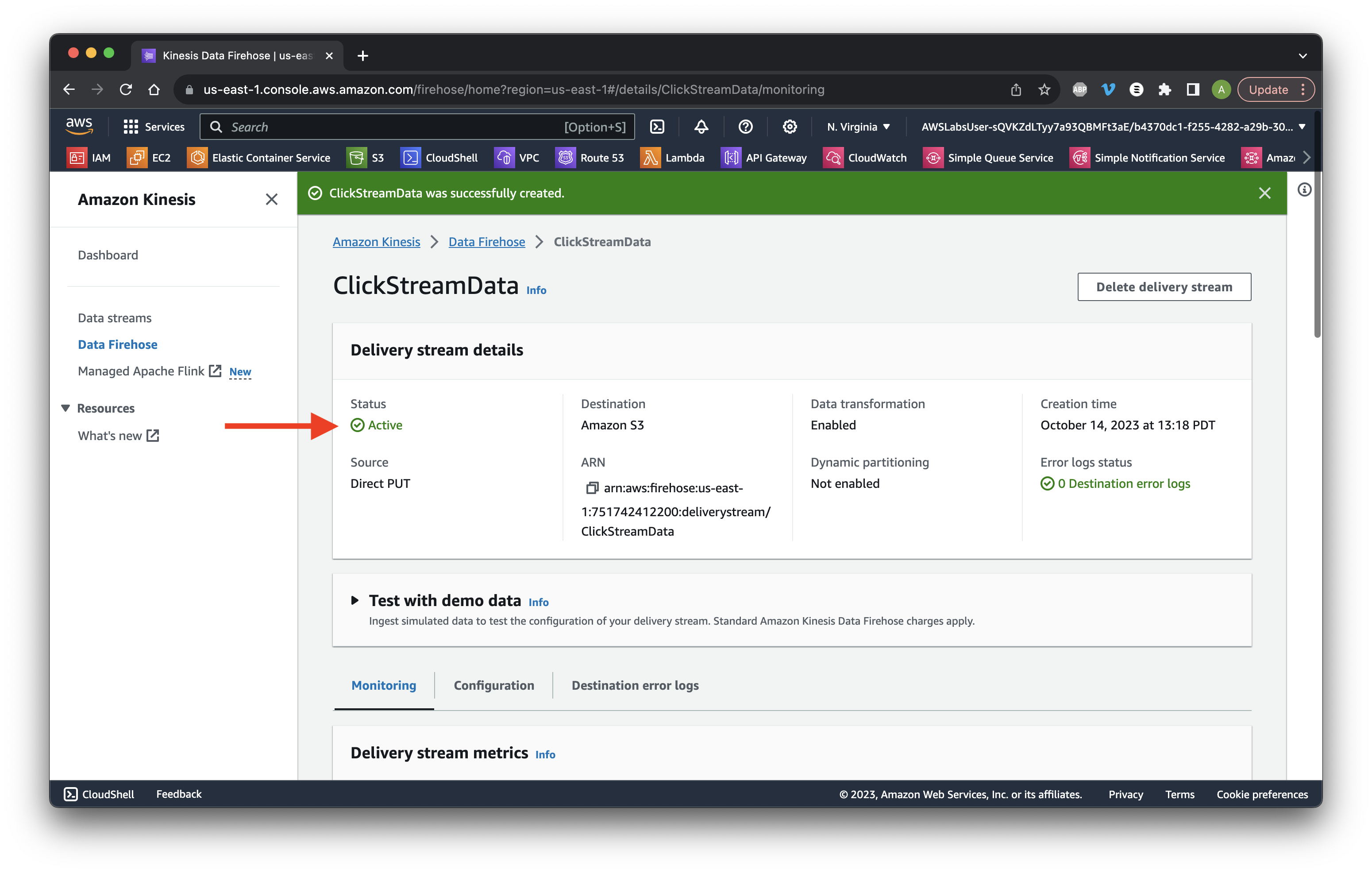
Wait until the status becomes Active.
Search for and go to Glue.
Select Databases then click Add database.
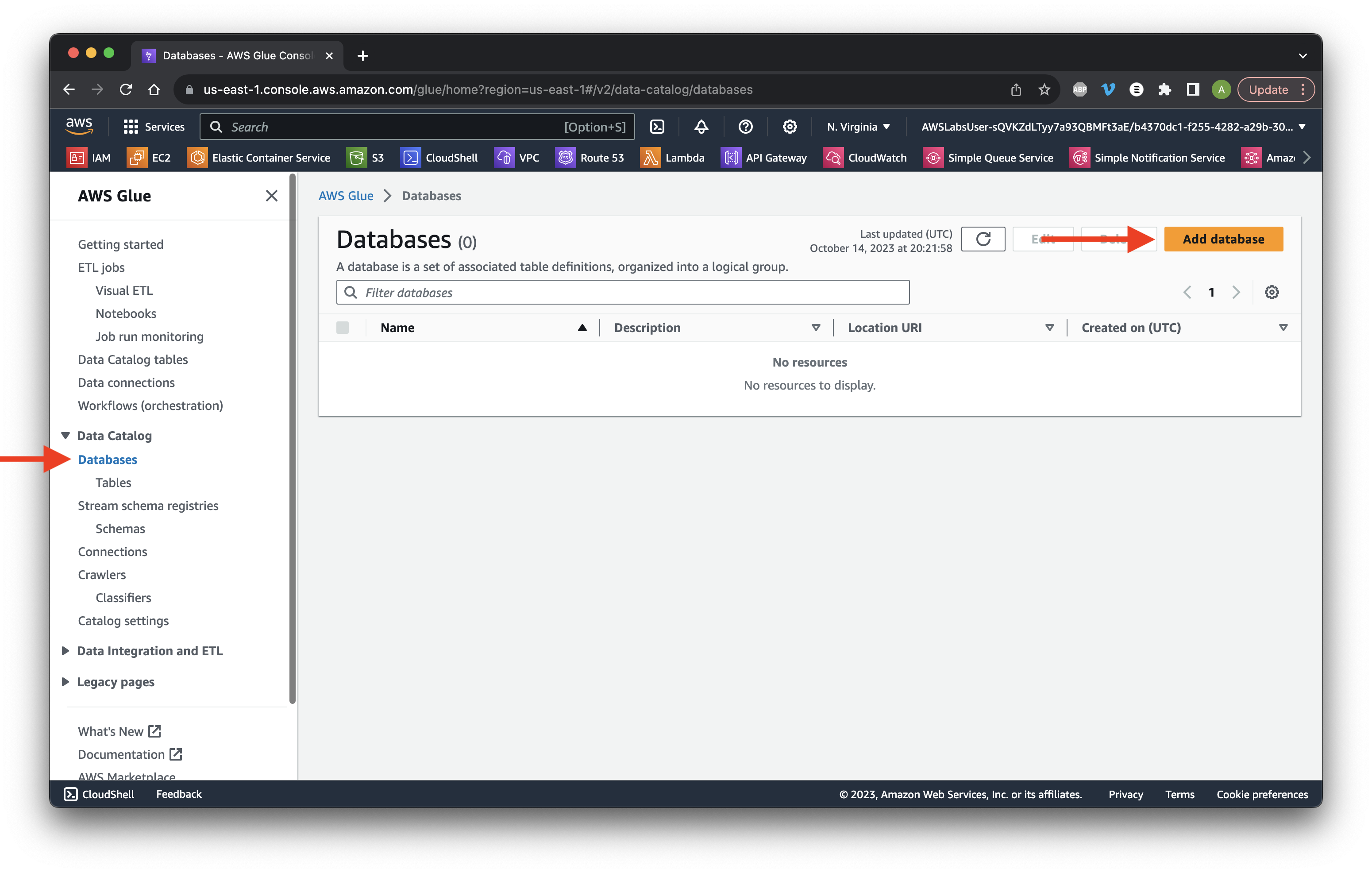
Name it firehose-inbound and click Create database.
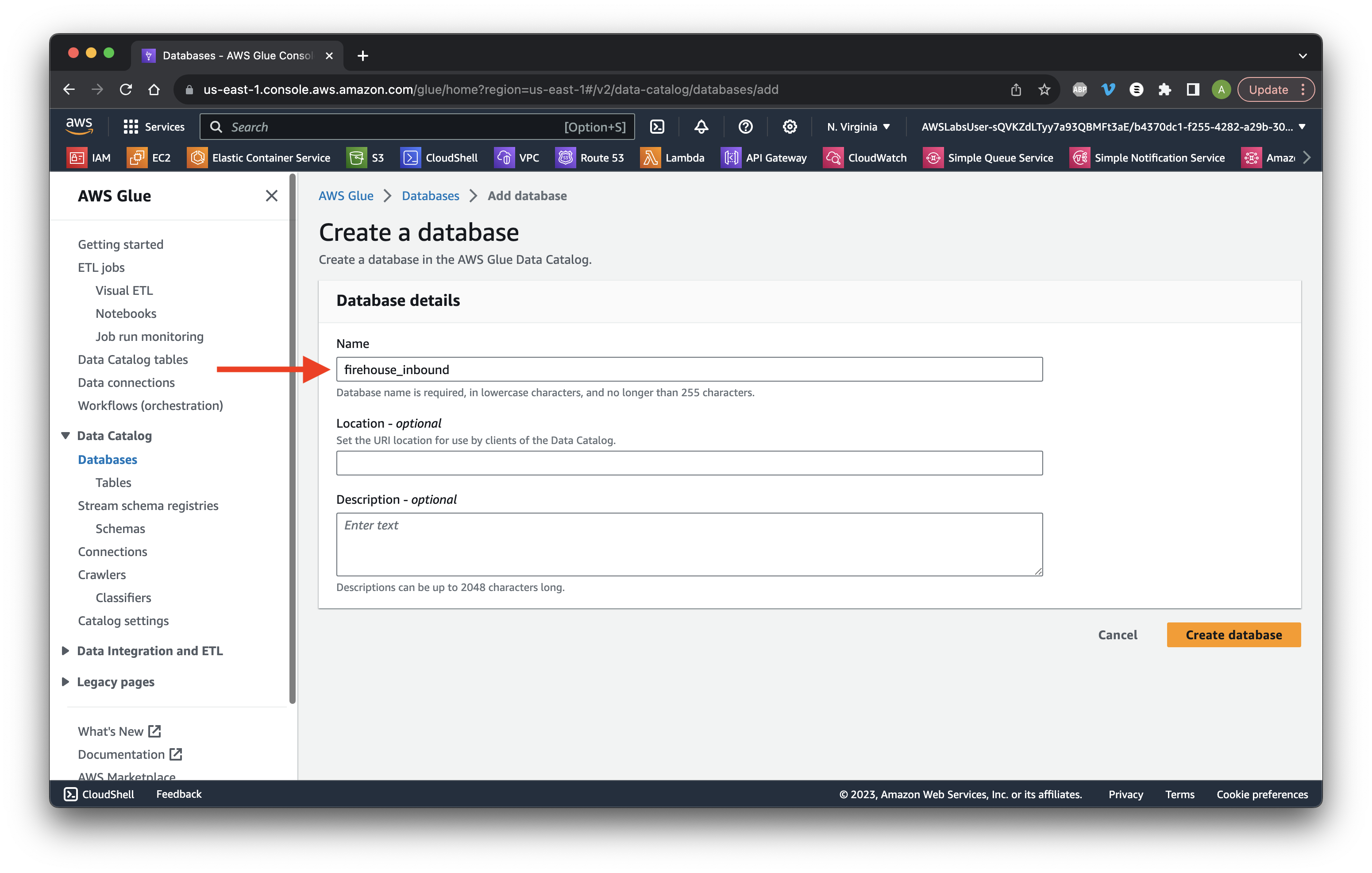
Select Tables and click Add table using crawler.
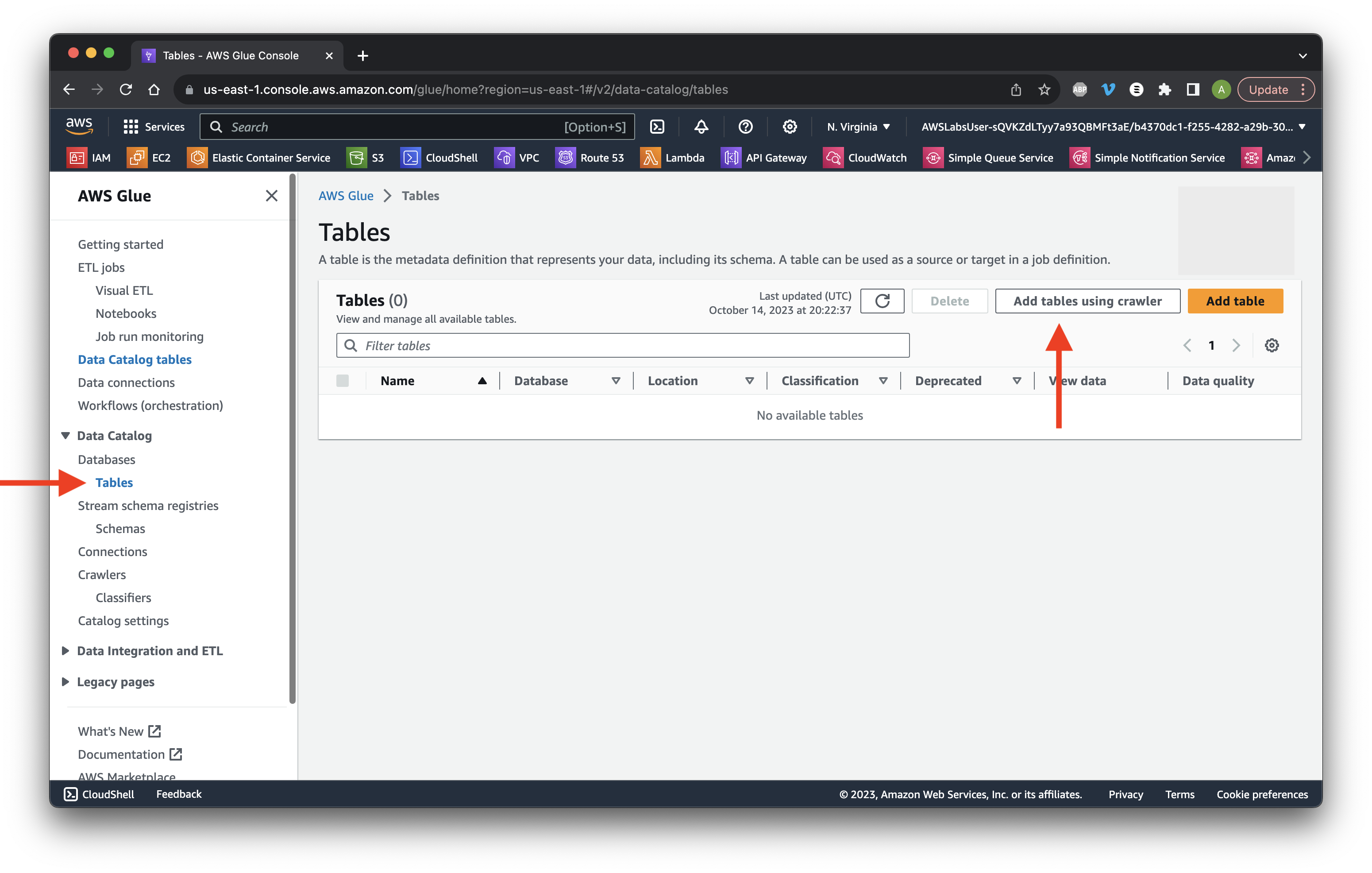
Name it crawl_processed_data and click Next.
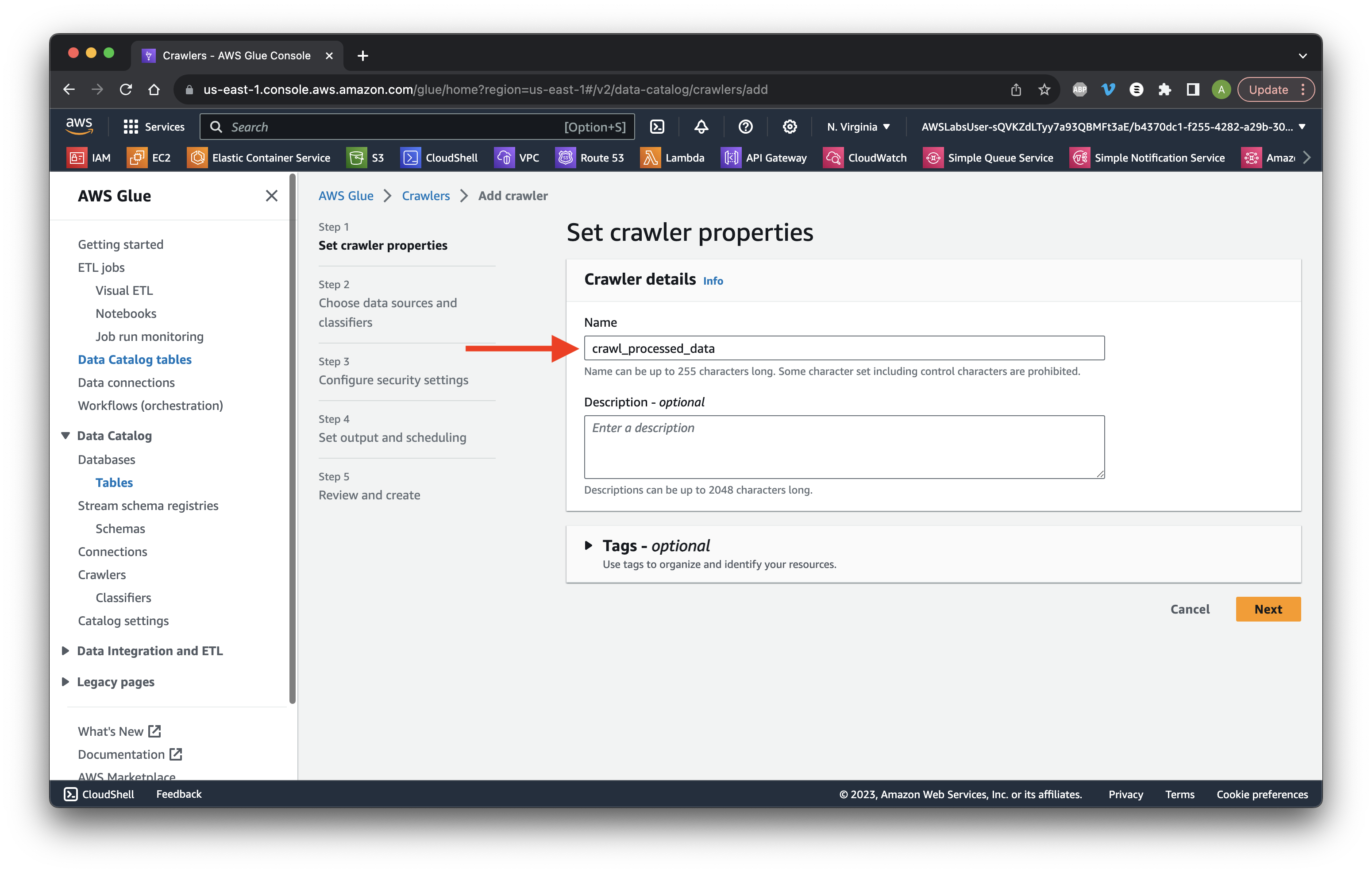
Click Add a data source.
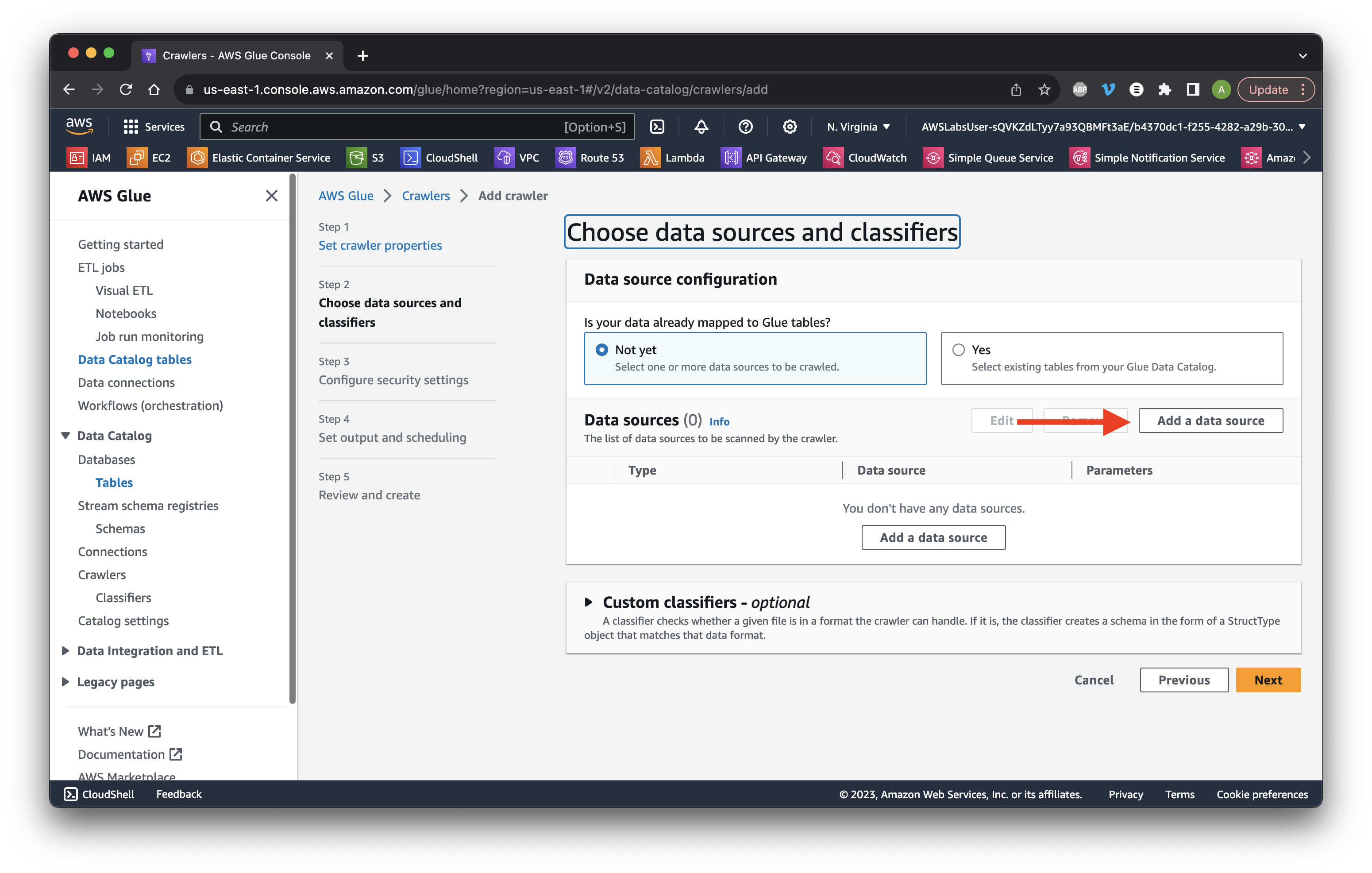
Choose S3 as the Data source and click Browse S3.
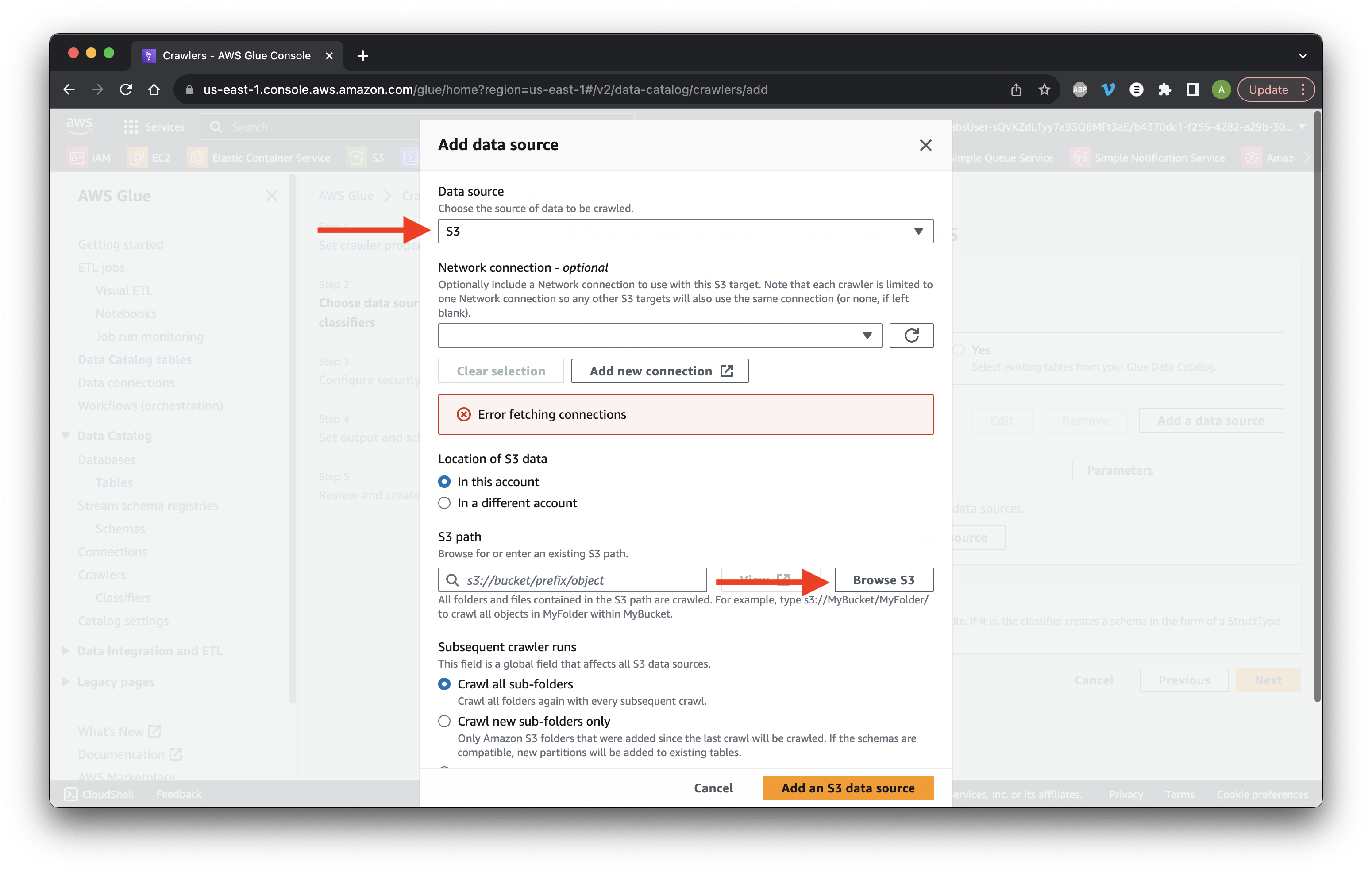
Choose the data bucket and click Choose.
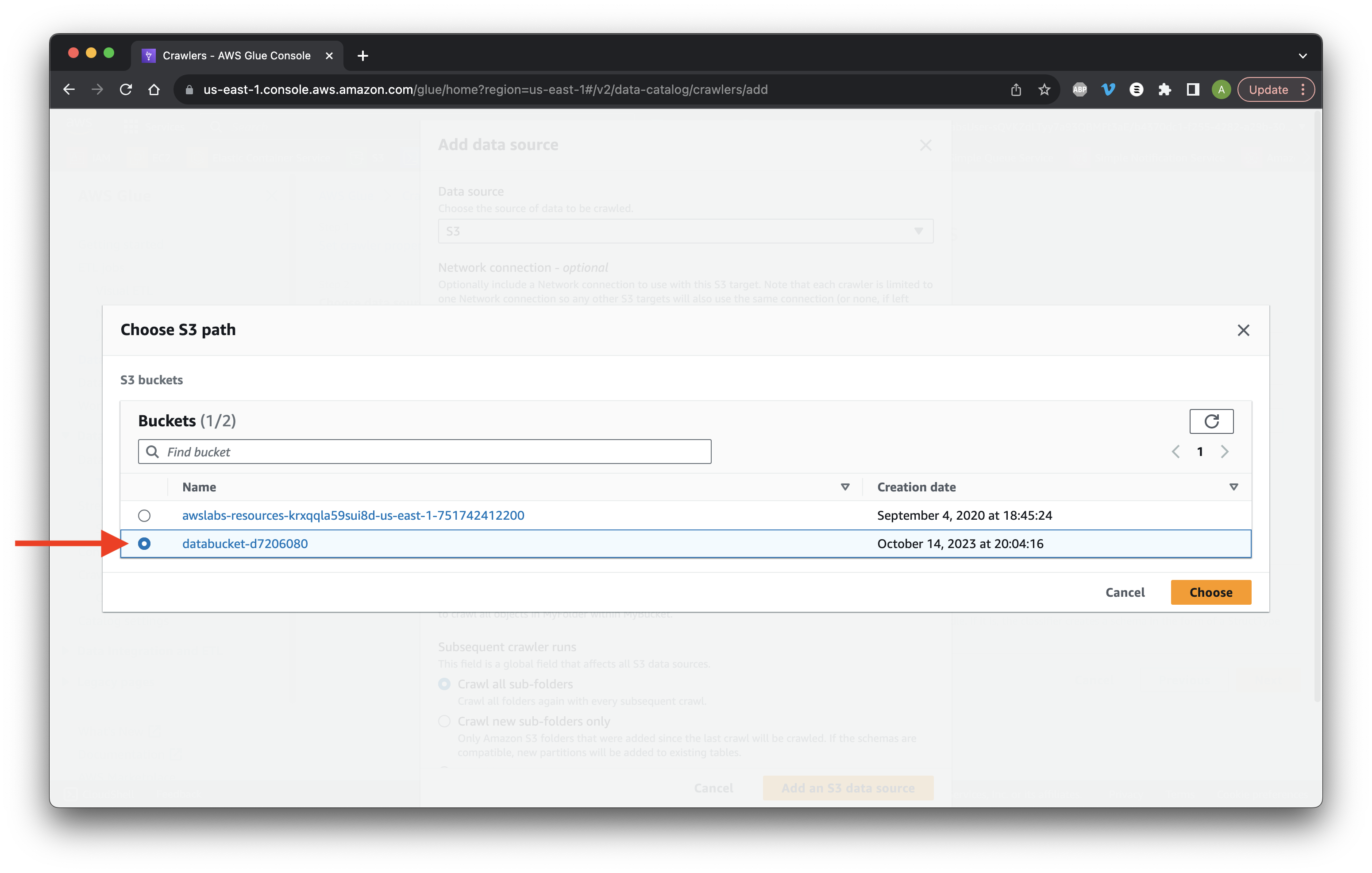
At the end of the S3 path add /processed_data/ and click Add an S3 data source.
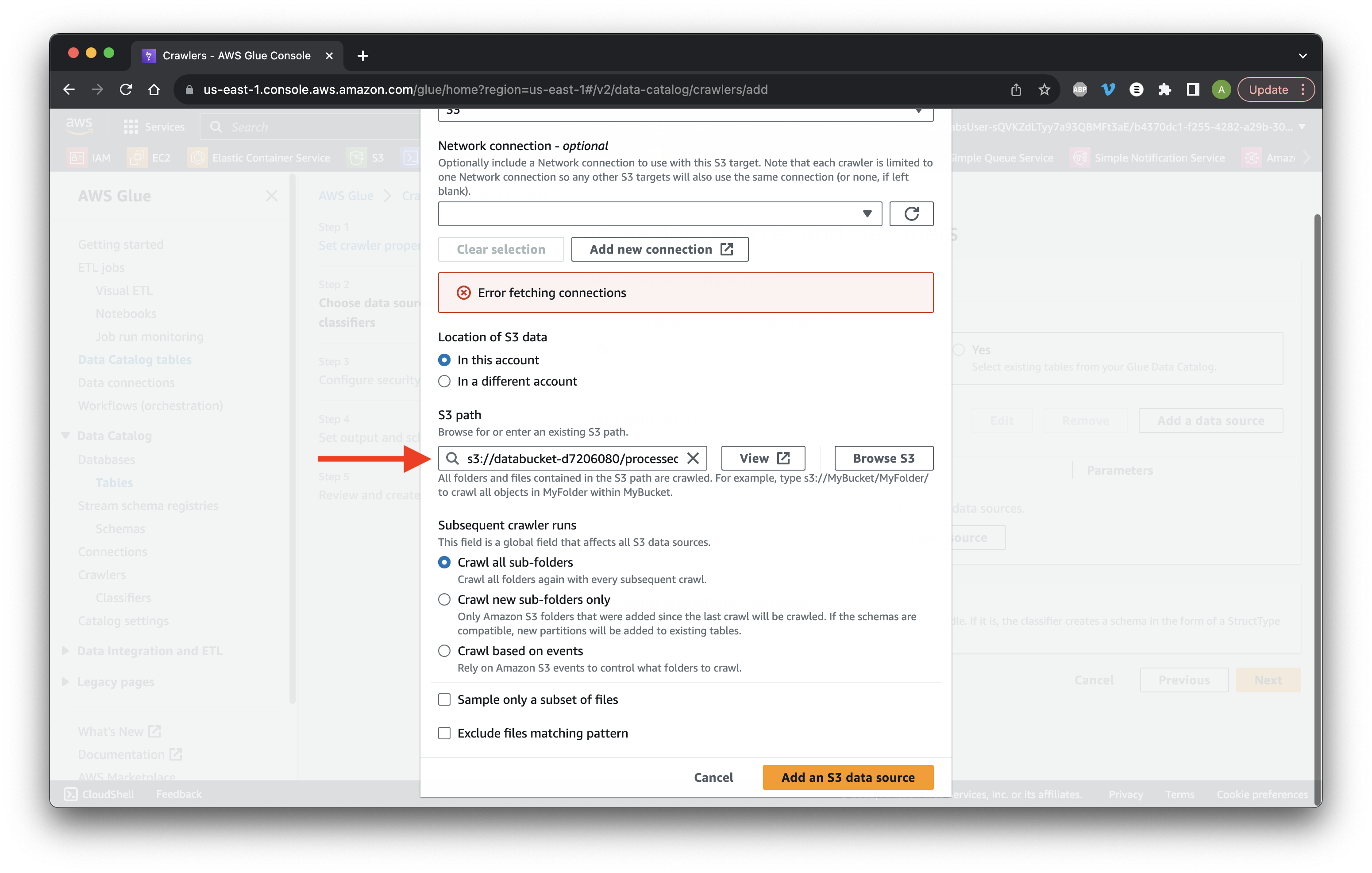
Select the bucket and Click Next.
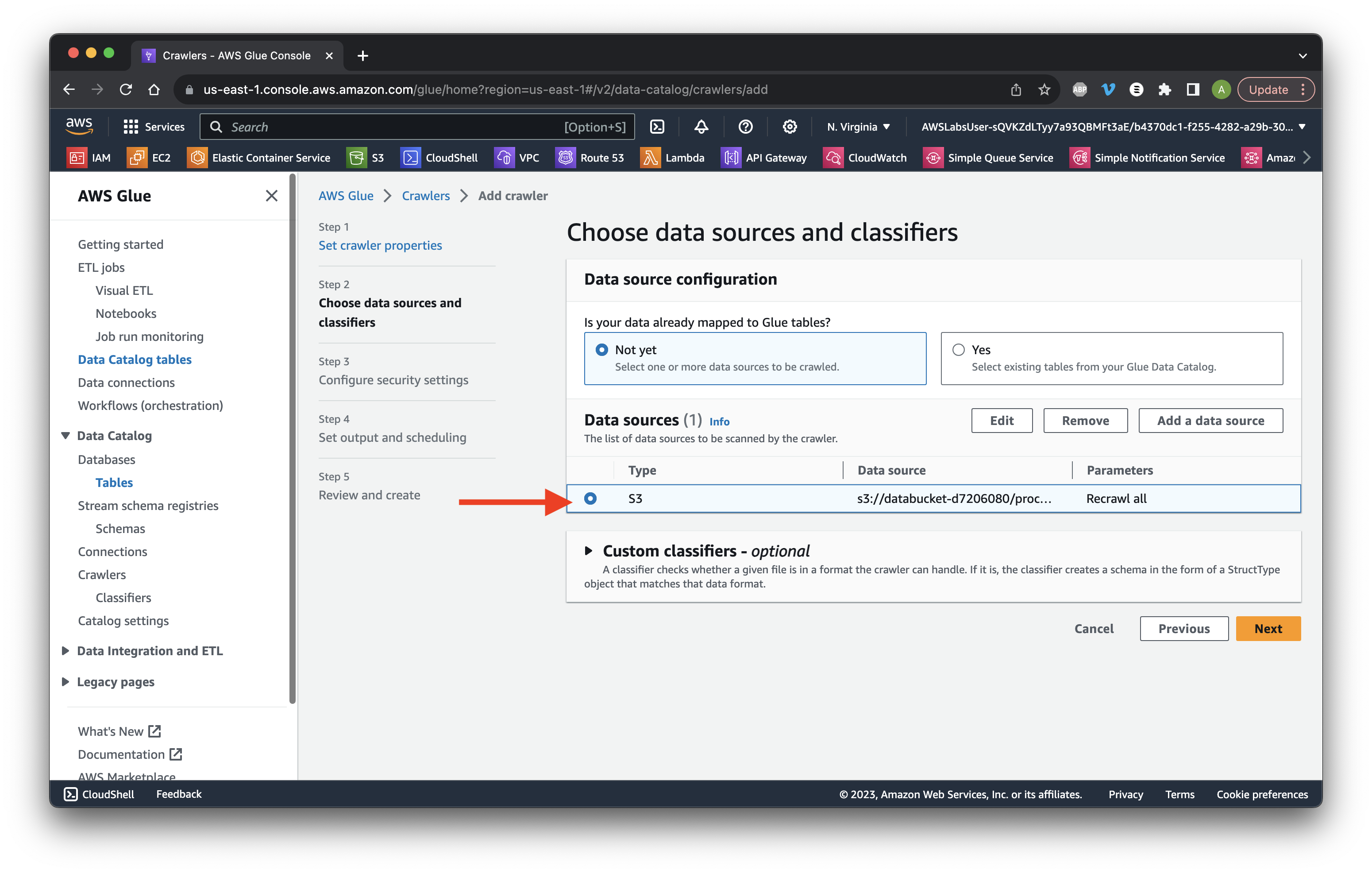
Click Create new IAM role.
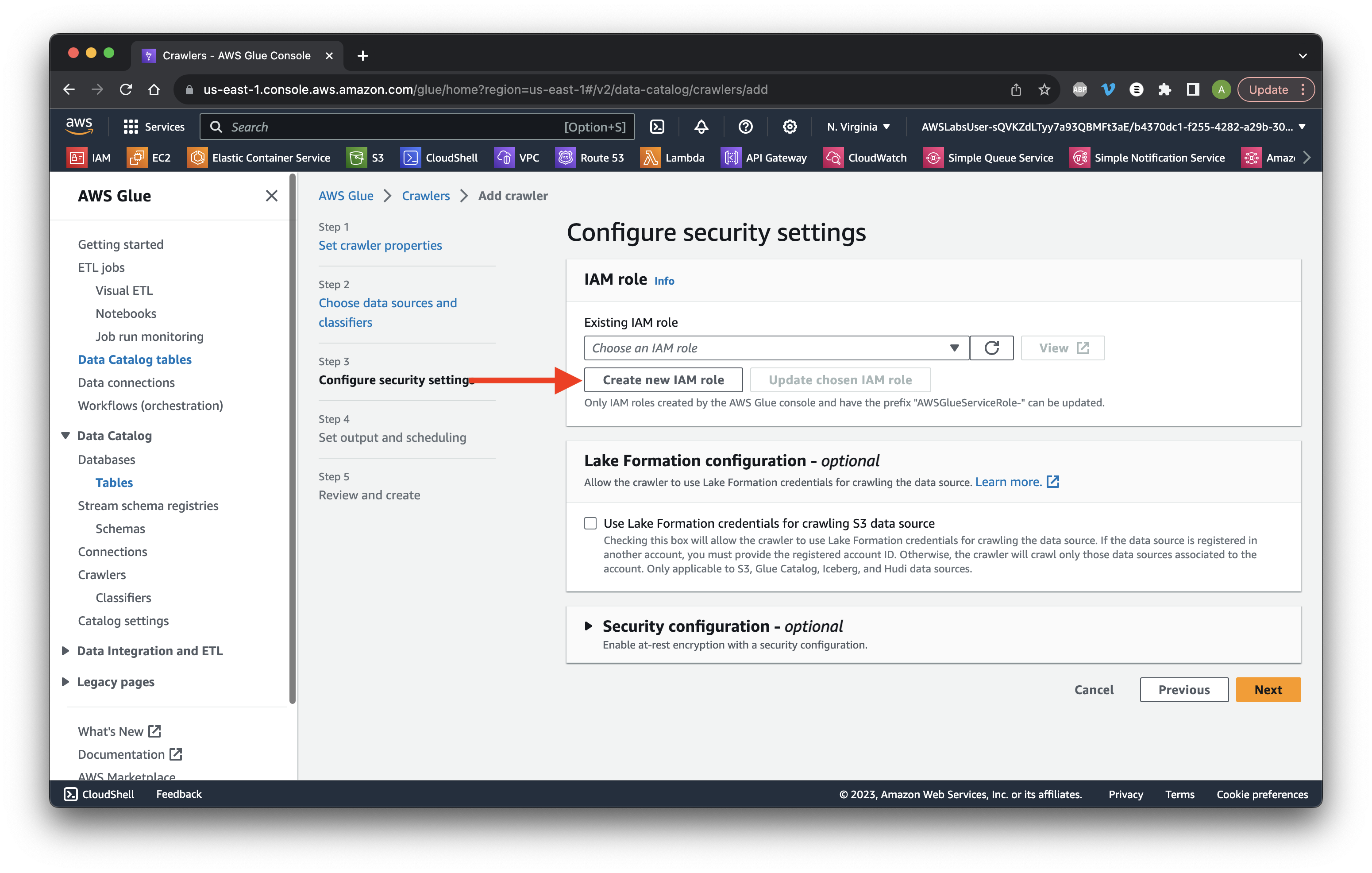
Add DataIngestion to the value.
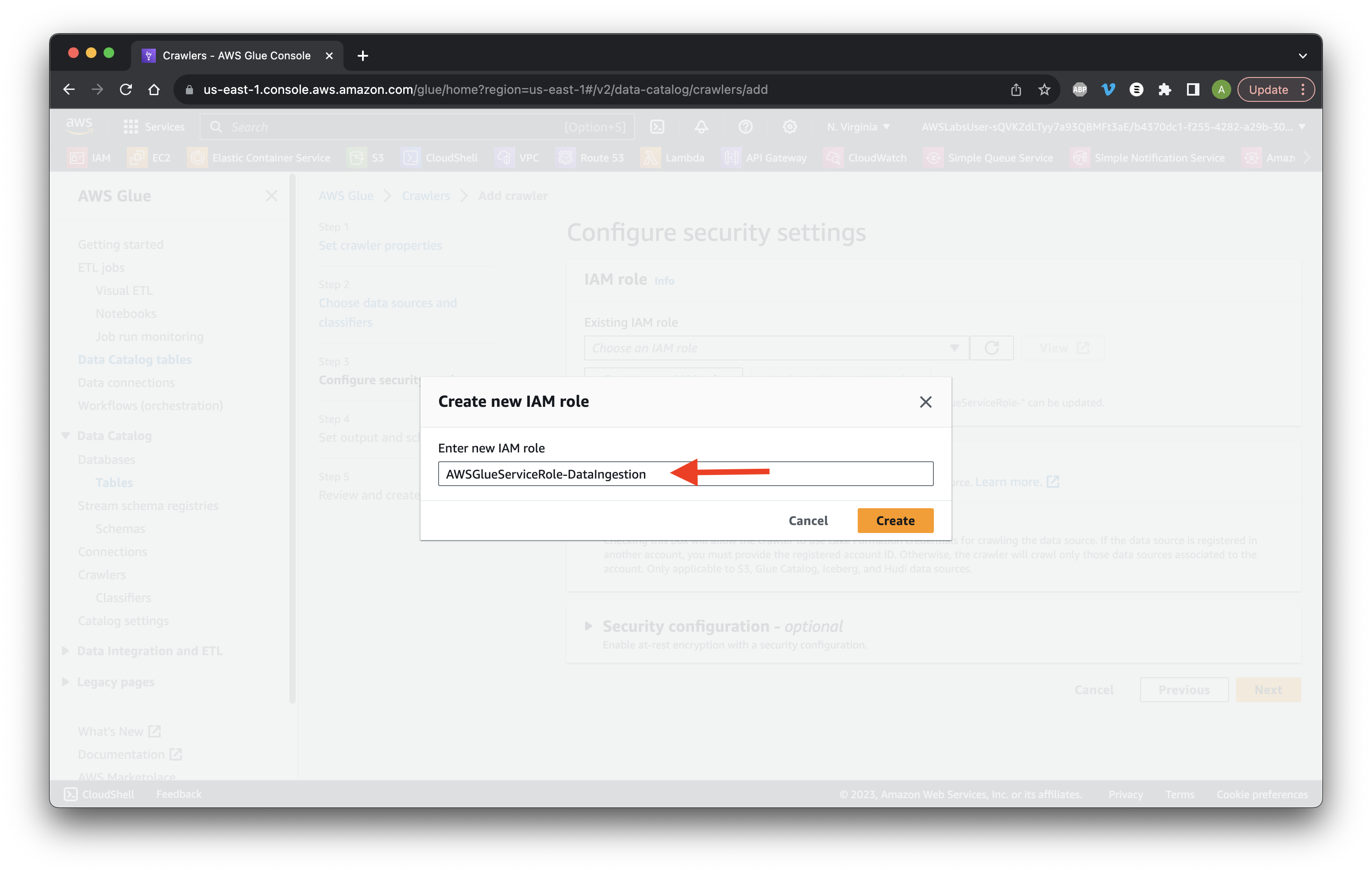
Ensure the IAM role was created then click Next.
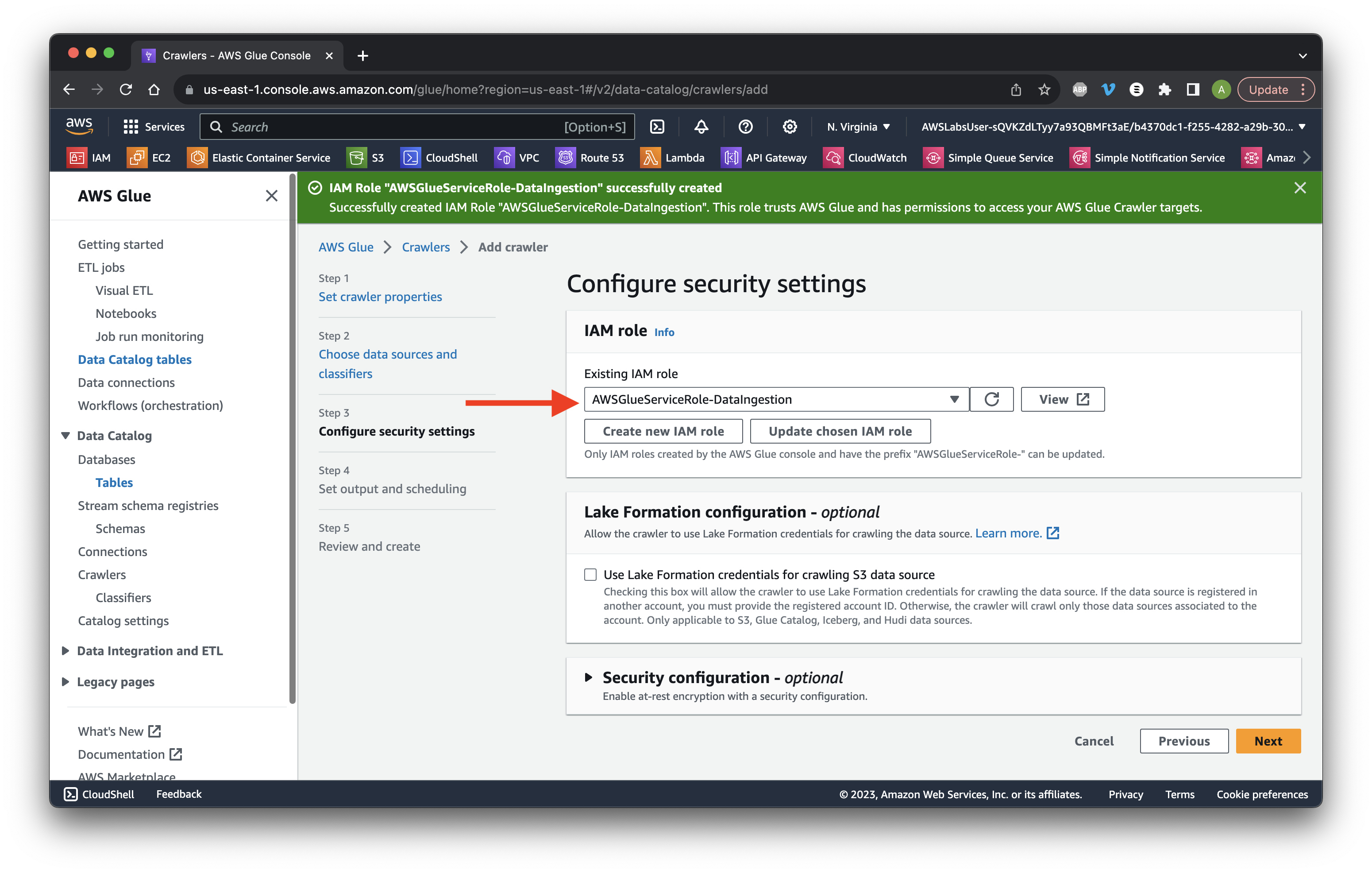
Select firehose-inbound as the target and scroll down to Crawler schedule.
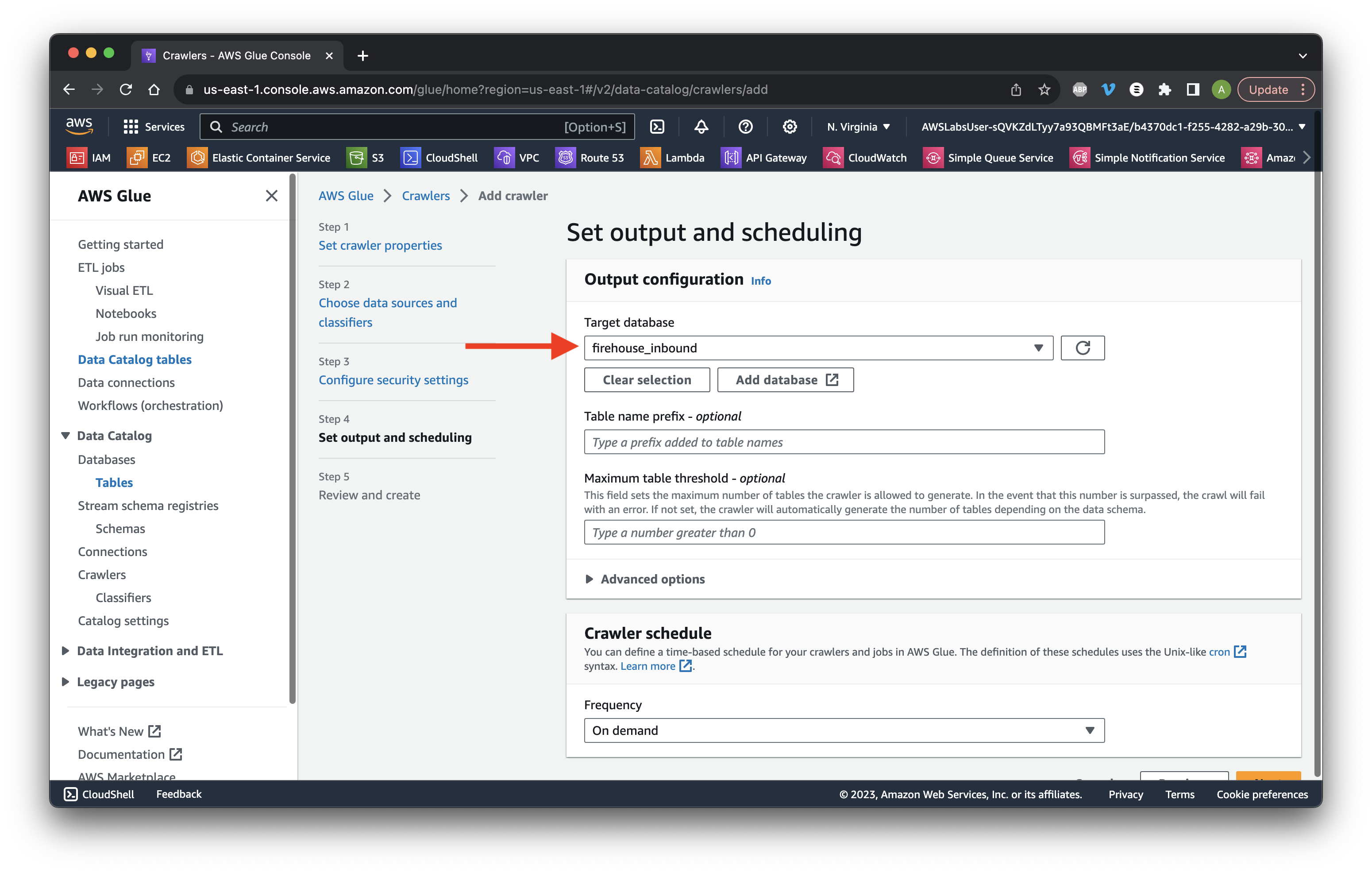
Choose Custom frequency and type */5 to run every 5 minutes. Scroll down and click Next. Click Create crawler.
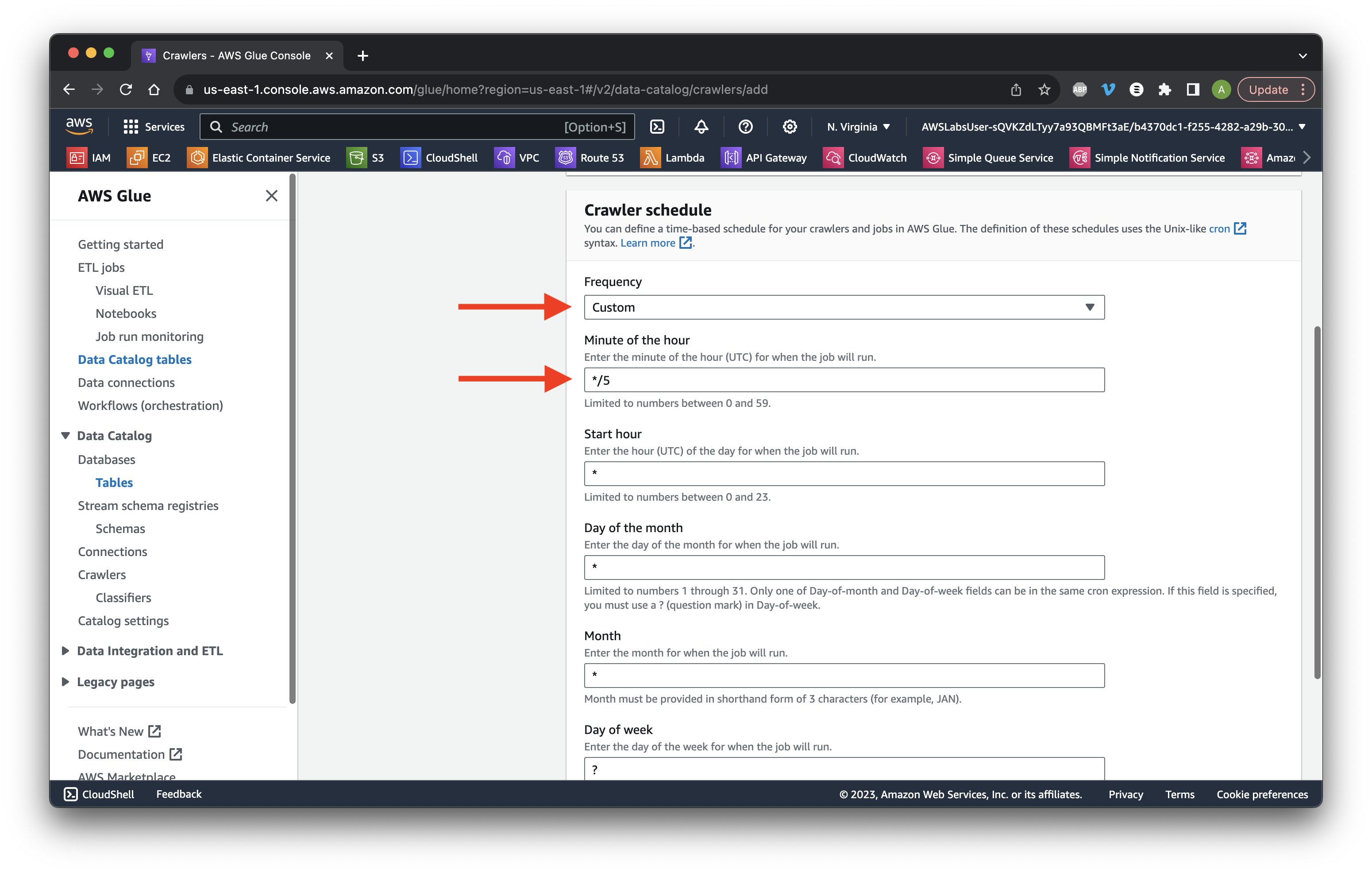
Head over to EC2 in the console. Choose Instances and select the check box of the Web UI instance. Copy the Public IPv4 Address.
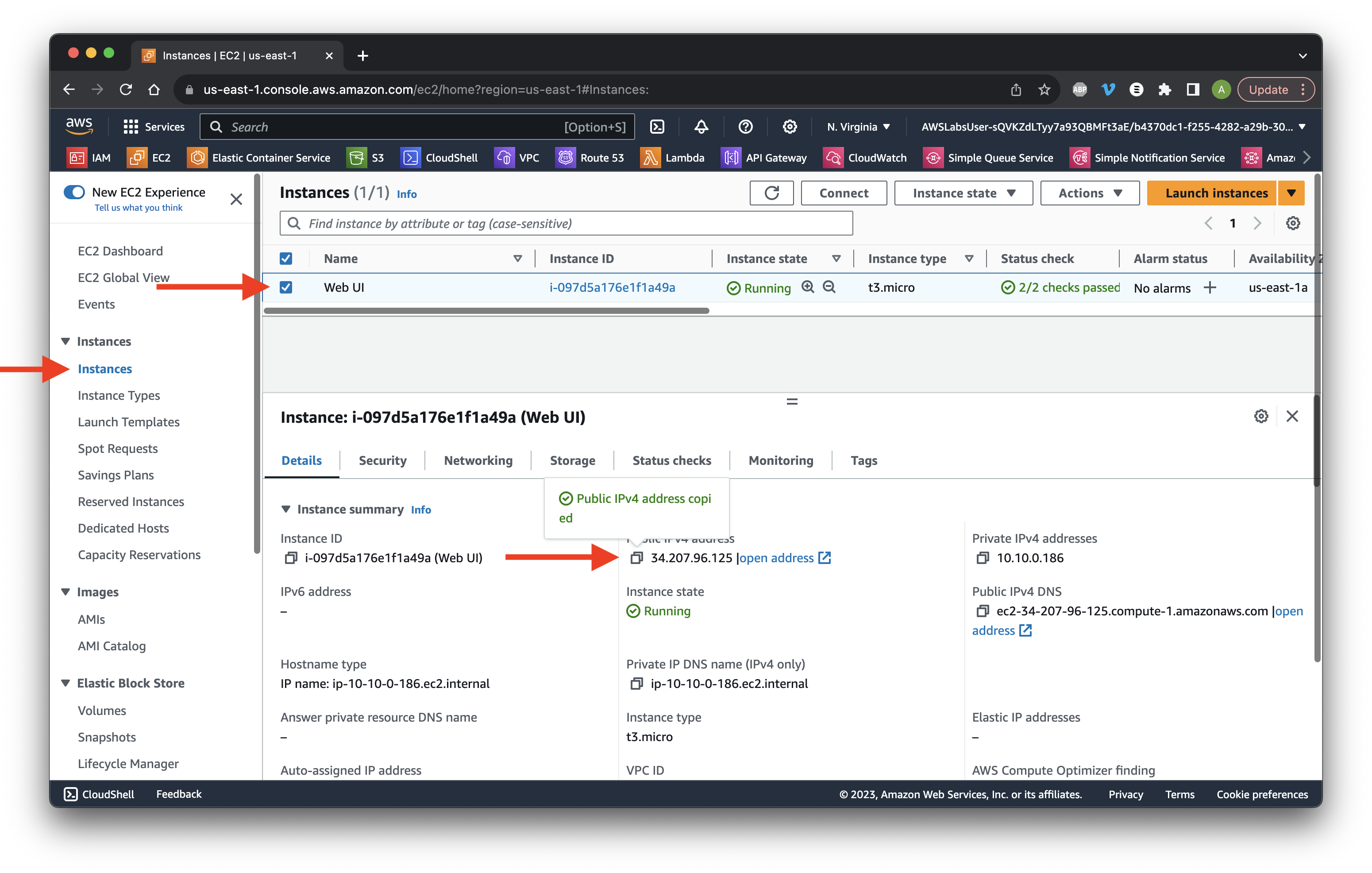
In a new page, paste the public IP we copied and add /firehose to the end. Type ClickStreamData and then click Submit.
Click Start test stream data.
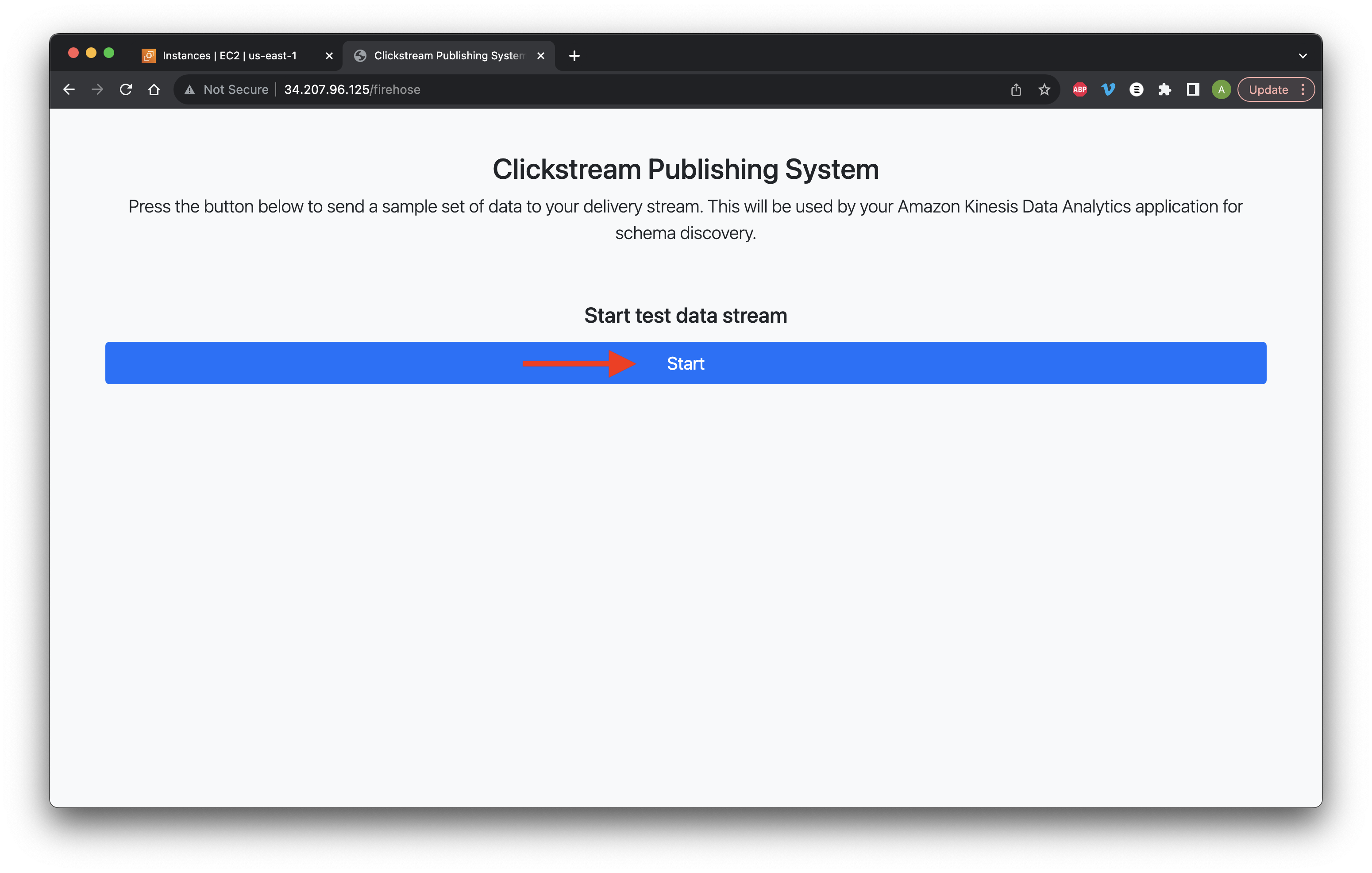
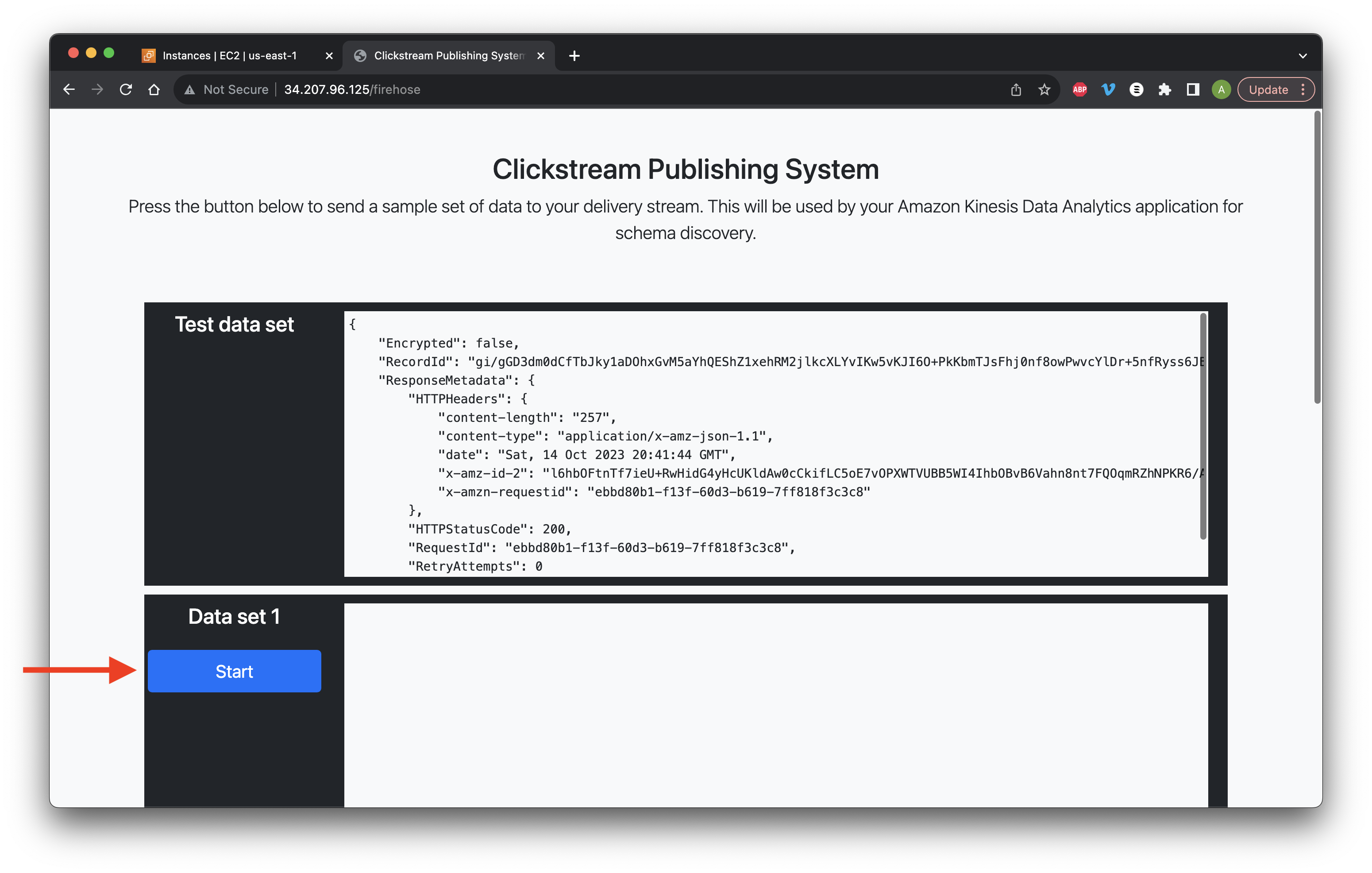
Click Start for Data set 1.
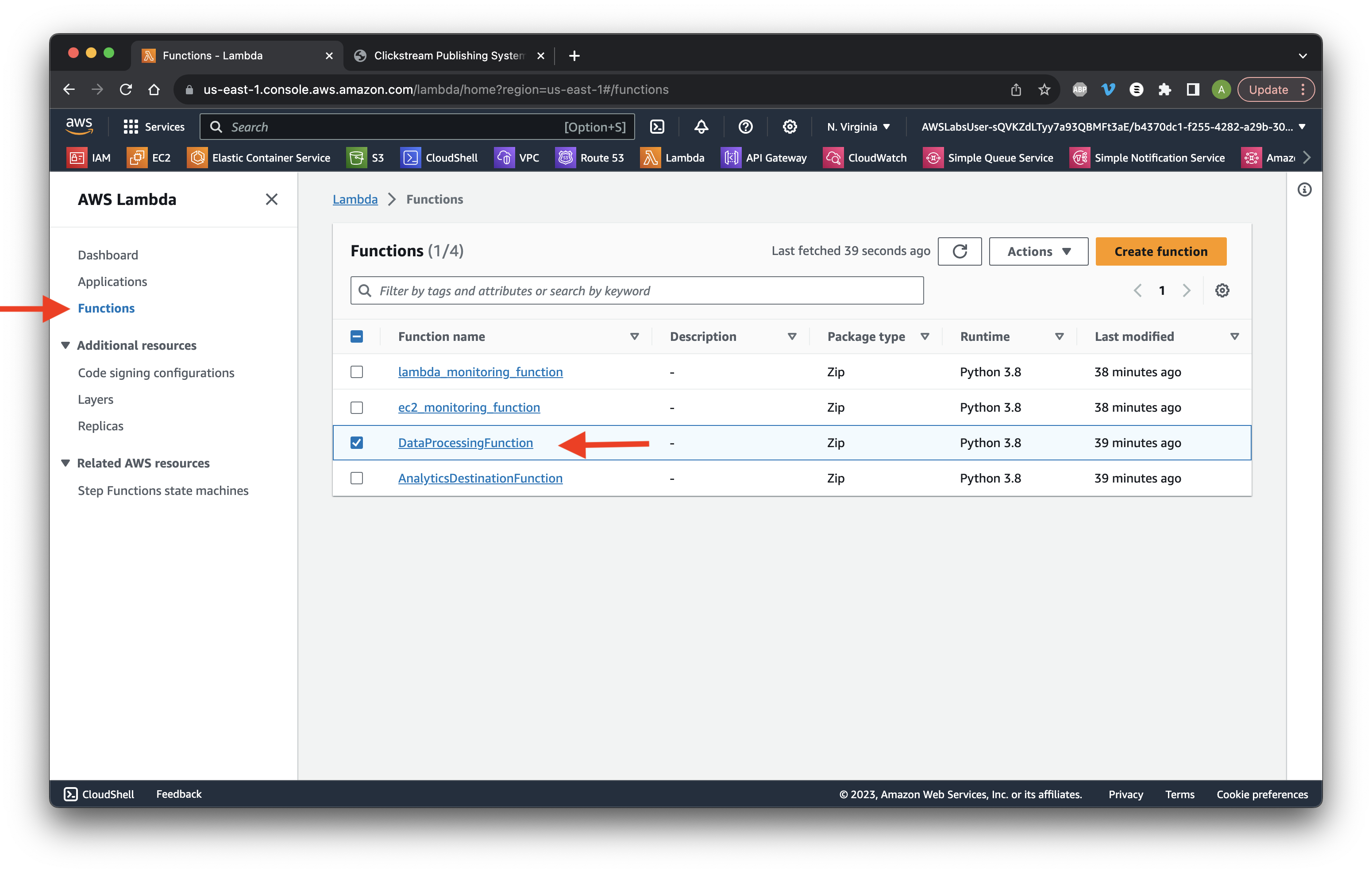
Go to the Lambda console and select Functions. Click the DataProcessingFunction name.
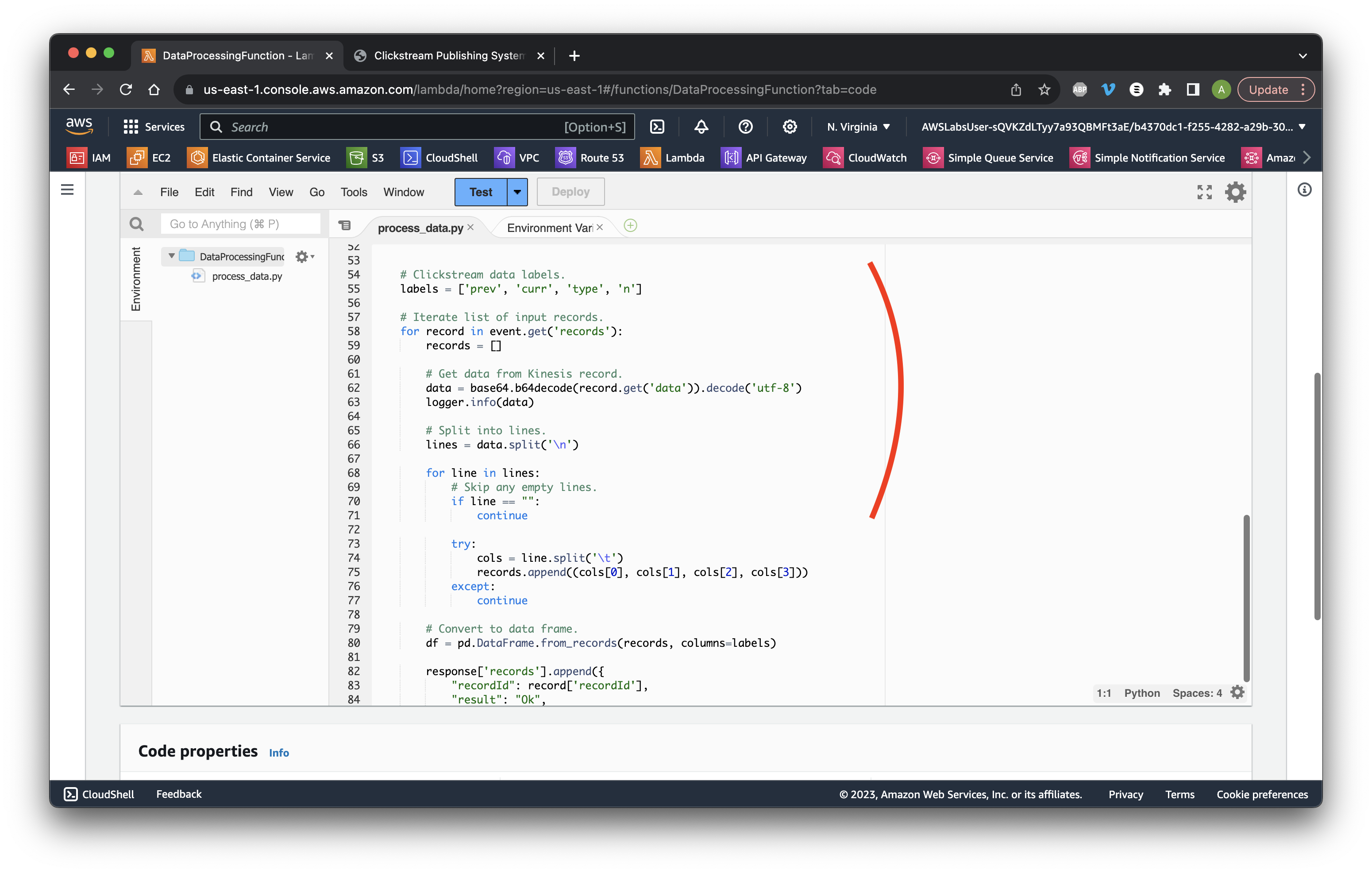
Go to the Code tab and review the Lambda function loop.
Go to the DynamoDB console and select Tables. Ensure the OutputTable is displayed.
Go to the S3 console and click the data bucket.
Click the processed_data/ name.
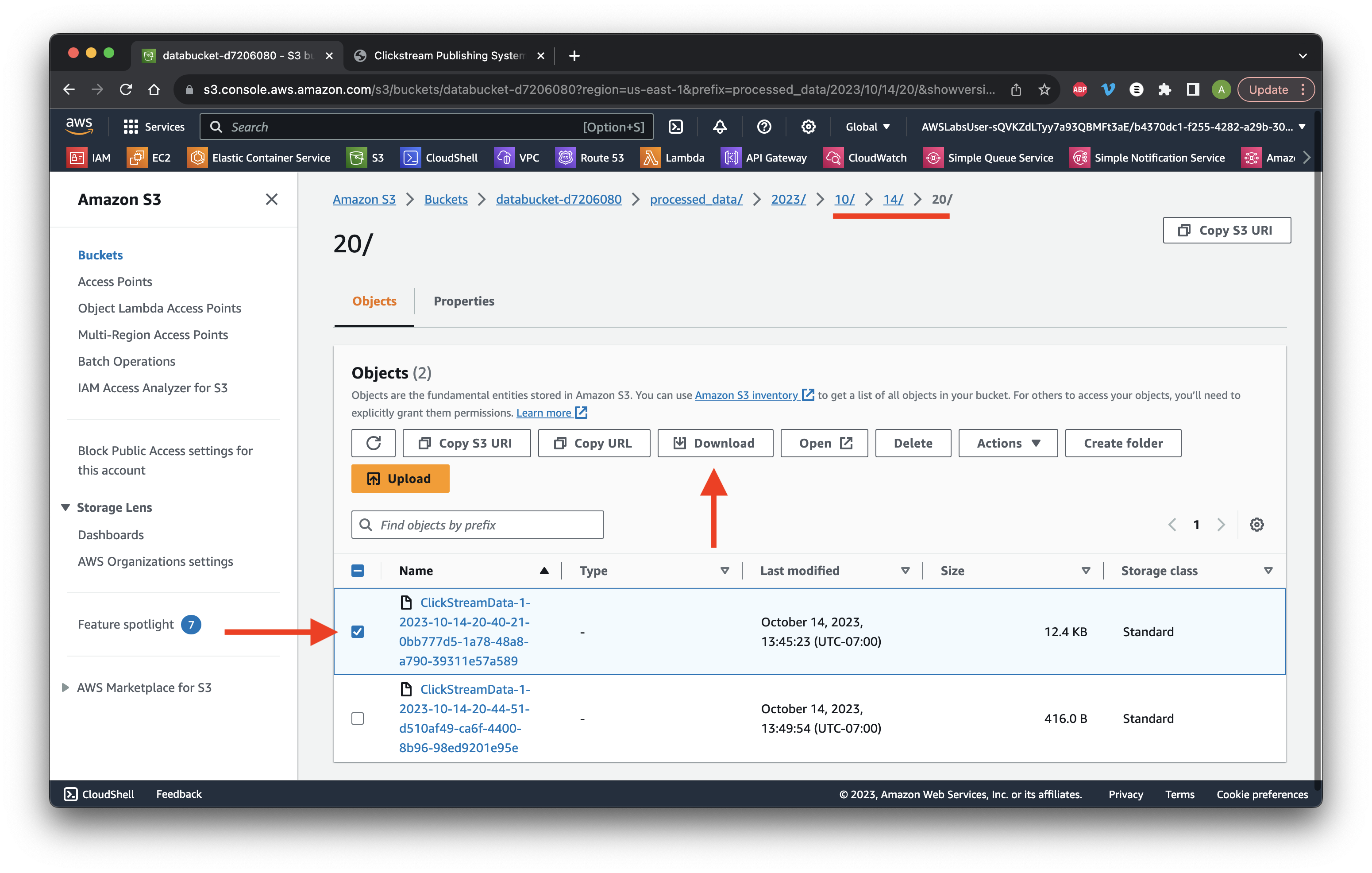
Navigate through the folders until we reach the ClickStreamData file. Select the top file name and click Download.
Open the downloaded file and ensure it is in CSV format.
Go to the Glue console and select Crawlers. Click the crawler Name we created earlier.
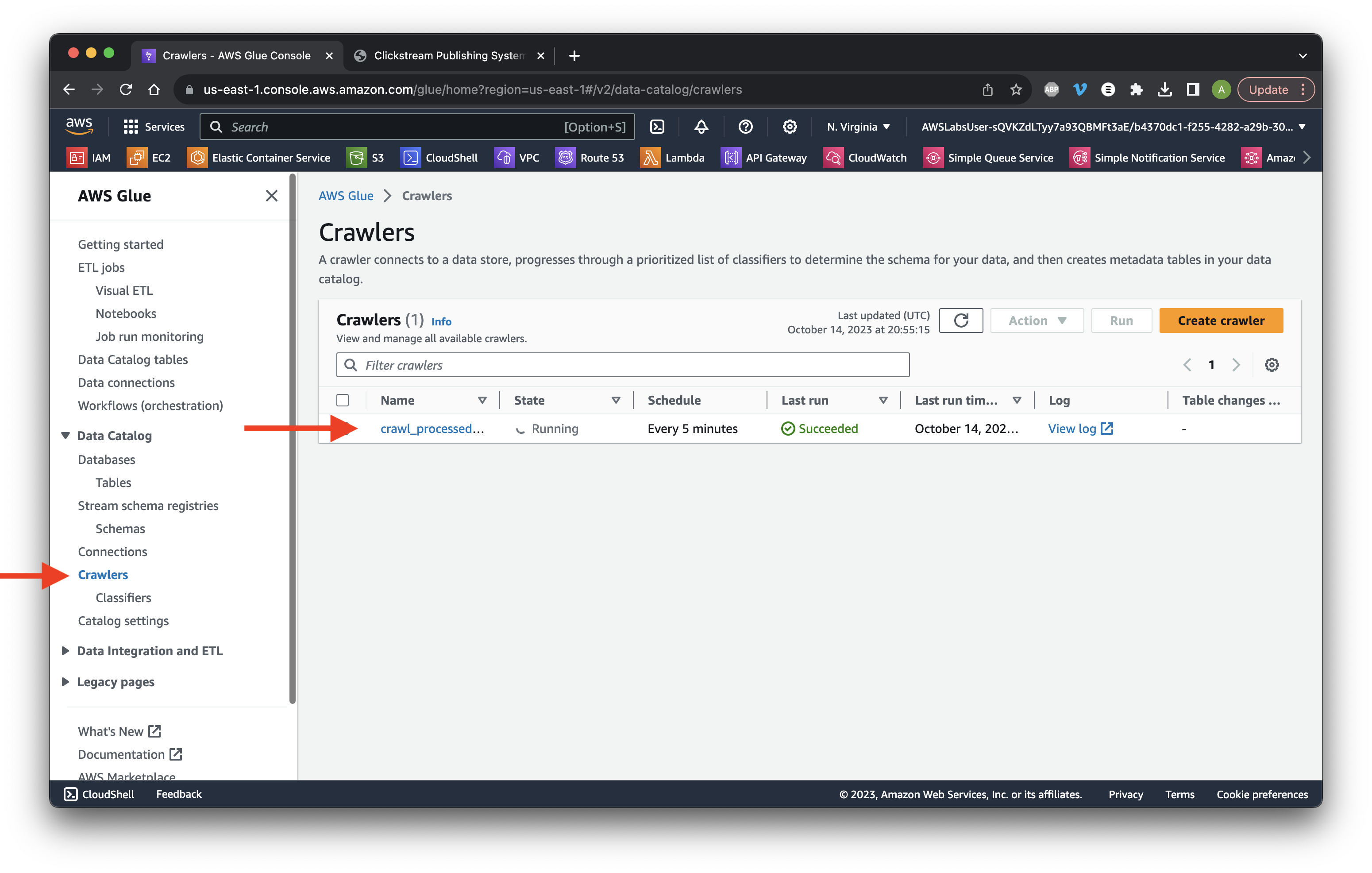
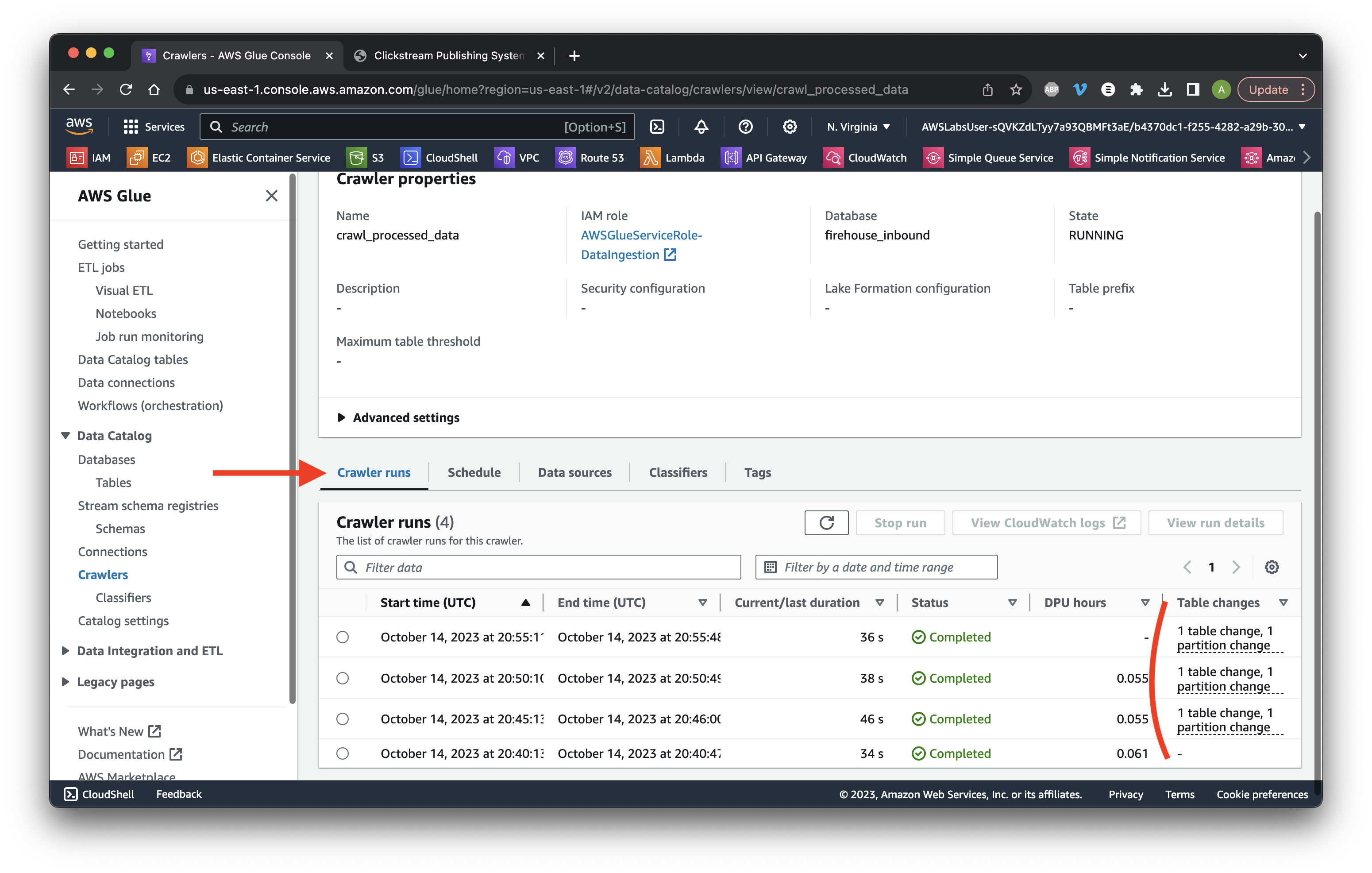
Scroll down to the Crawler runs tab and ensure that there is a minimum of one table change.
Go to the Athena console and select Query editor. Ensure we have the correct Database and Table.
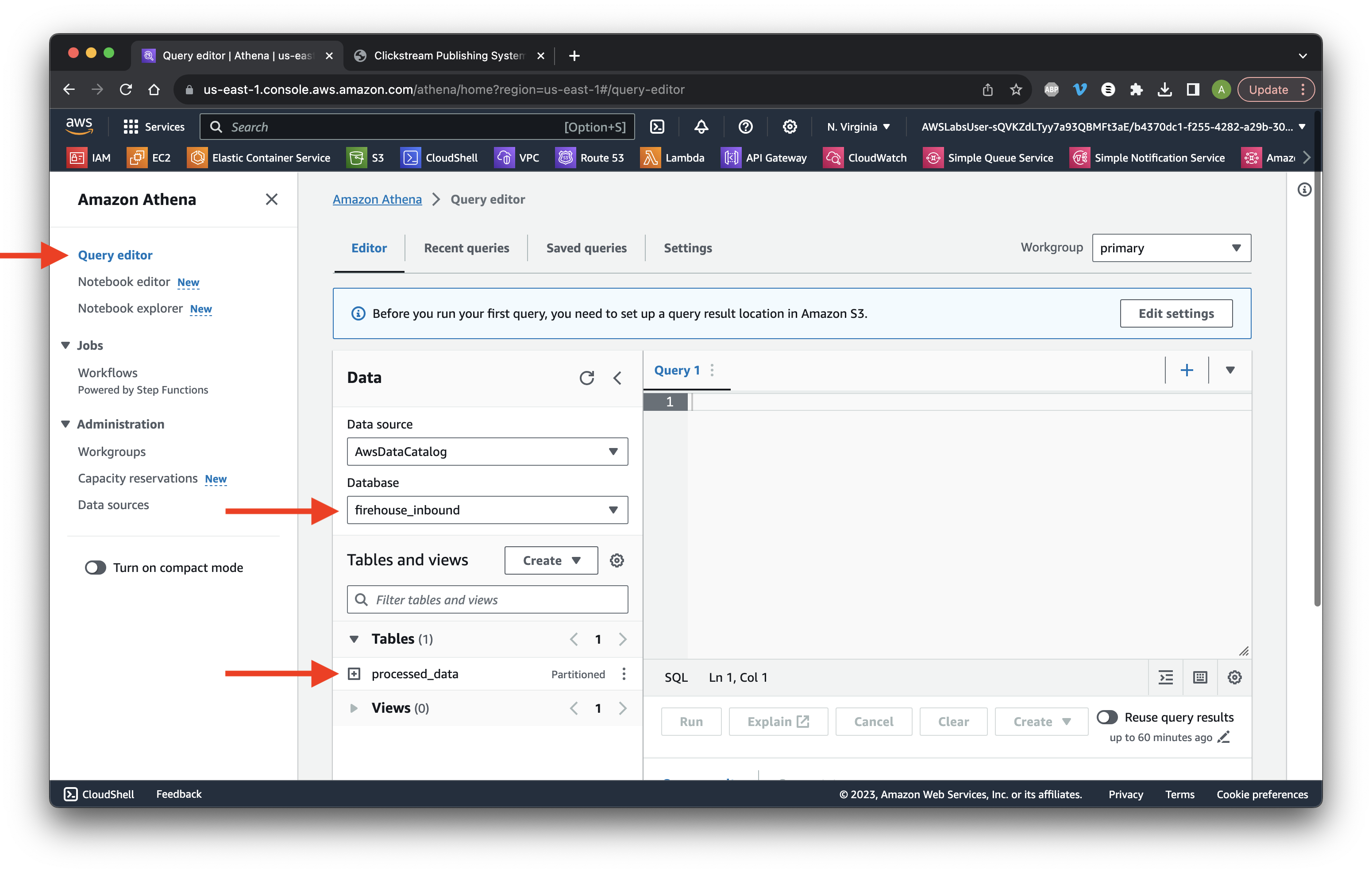
Go to the Settings tab and click Manage.
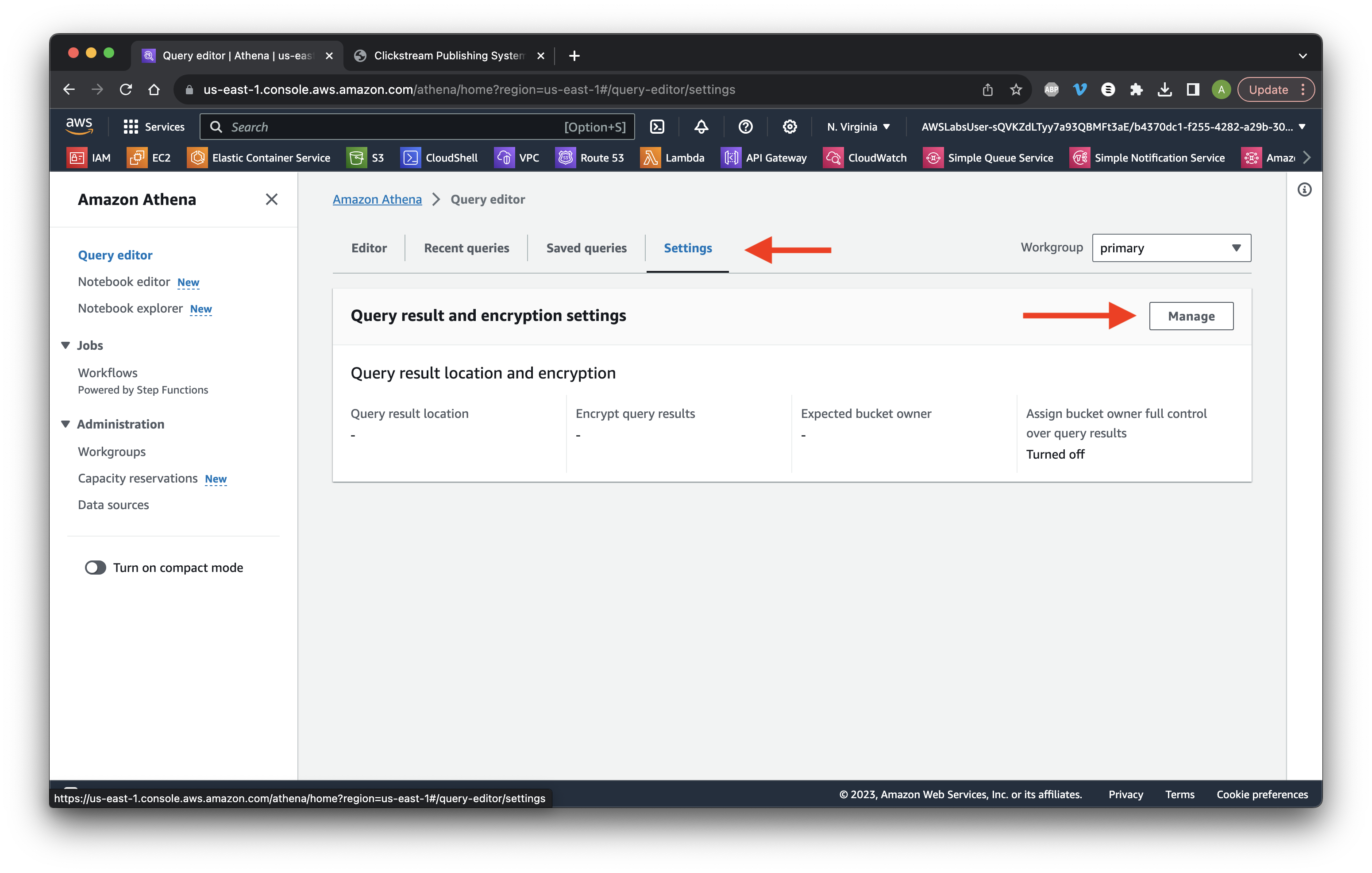
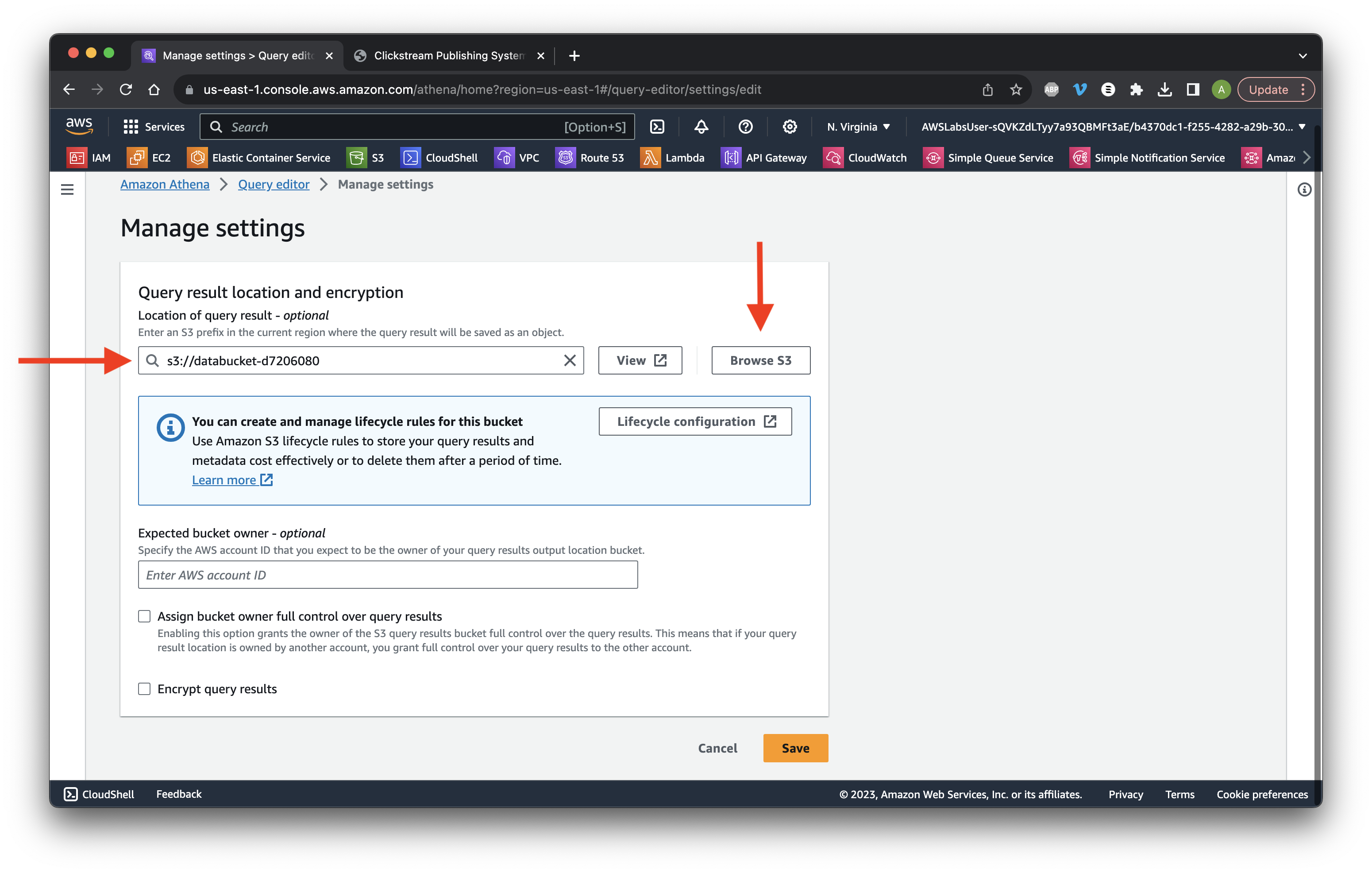
Click Browse and select the data bucket. Click Save.
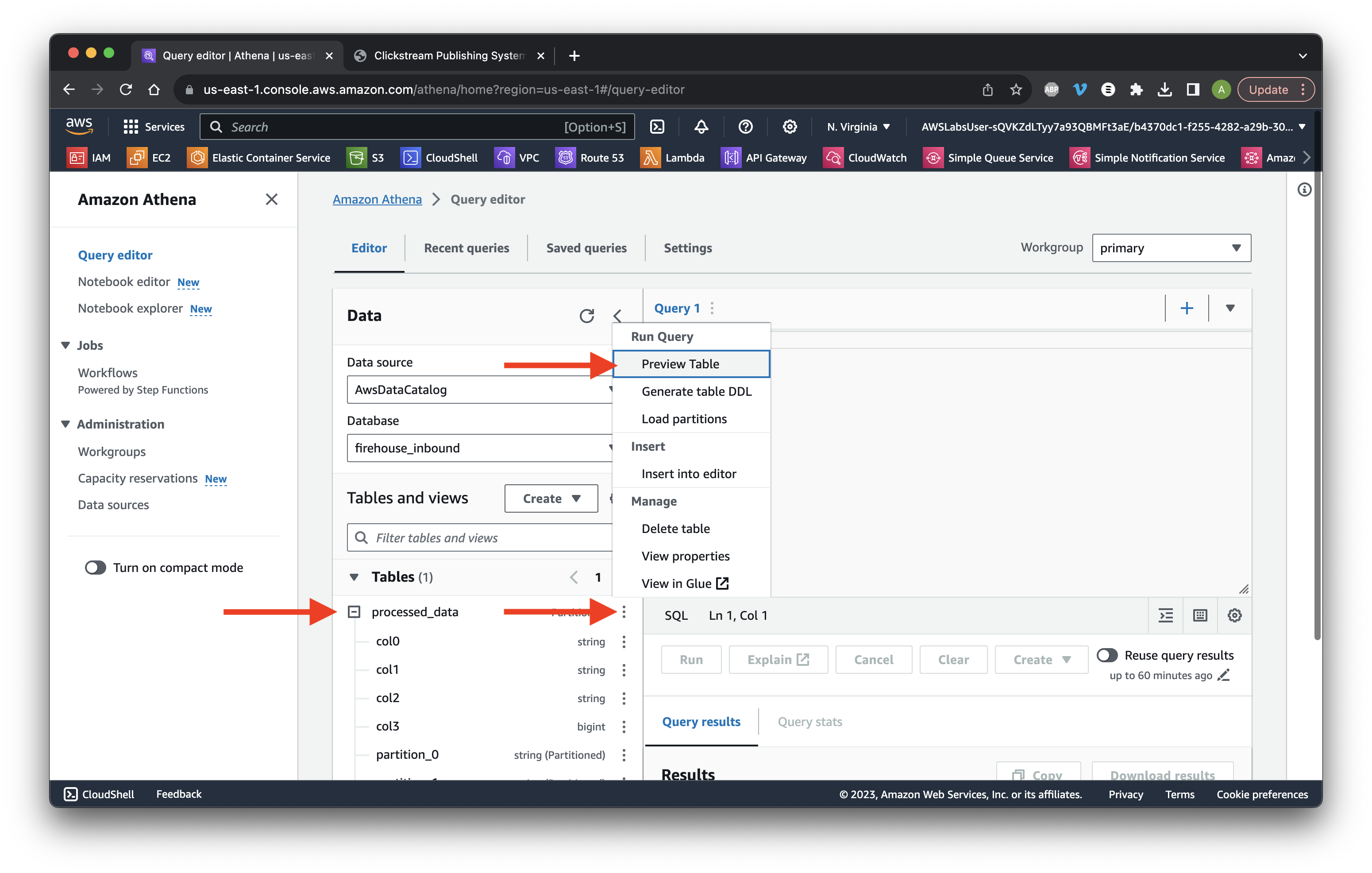
Go to the Editor tab and expand the processed_data table. Select the table ellipsis and click Preview table.
Click Run again.
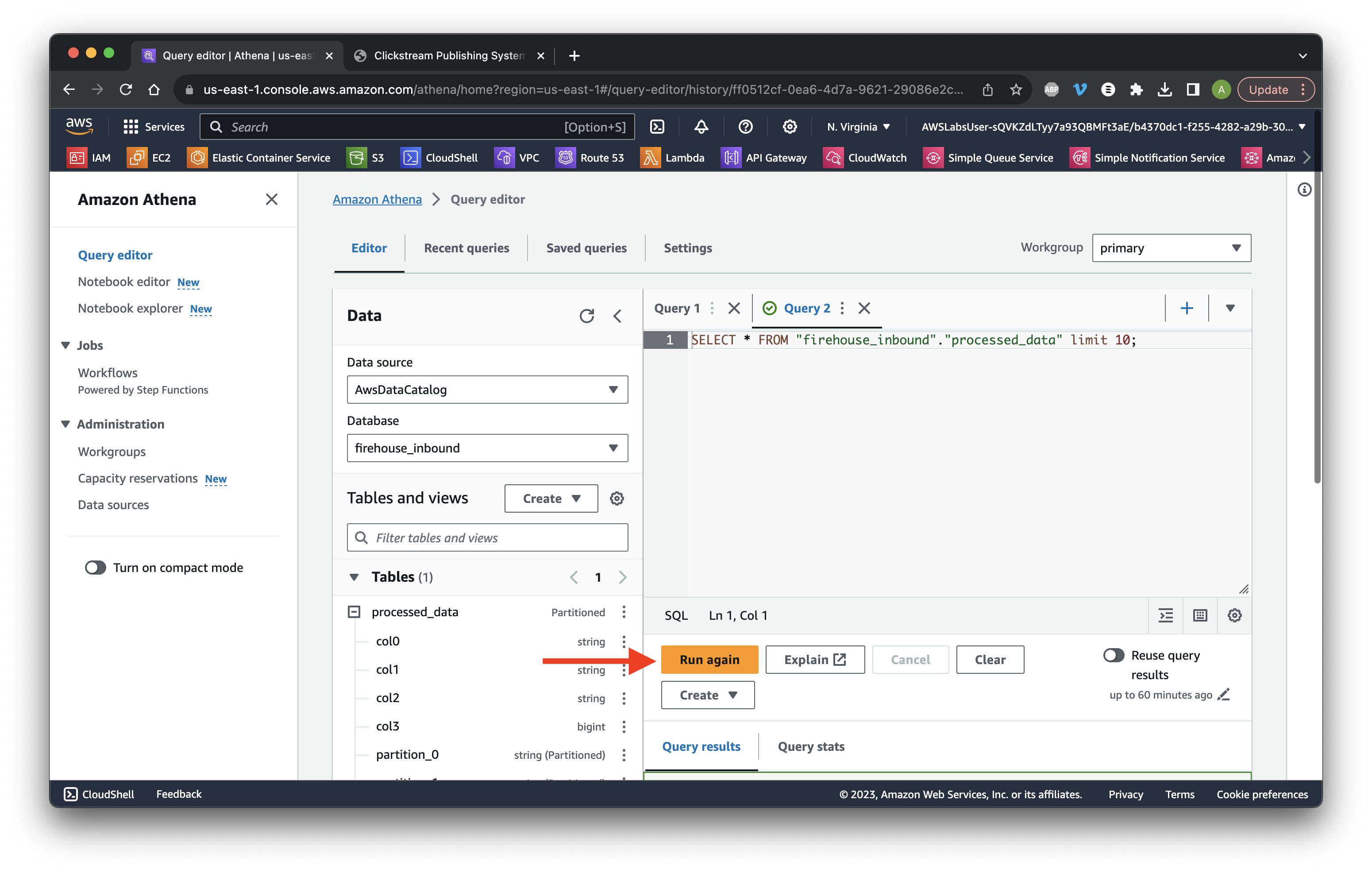
Scroll down to the results and review the partition data columns.
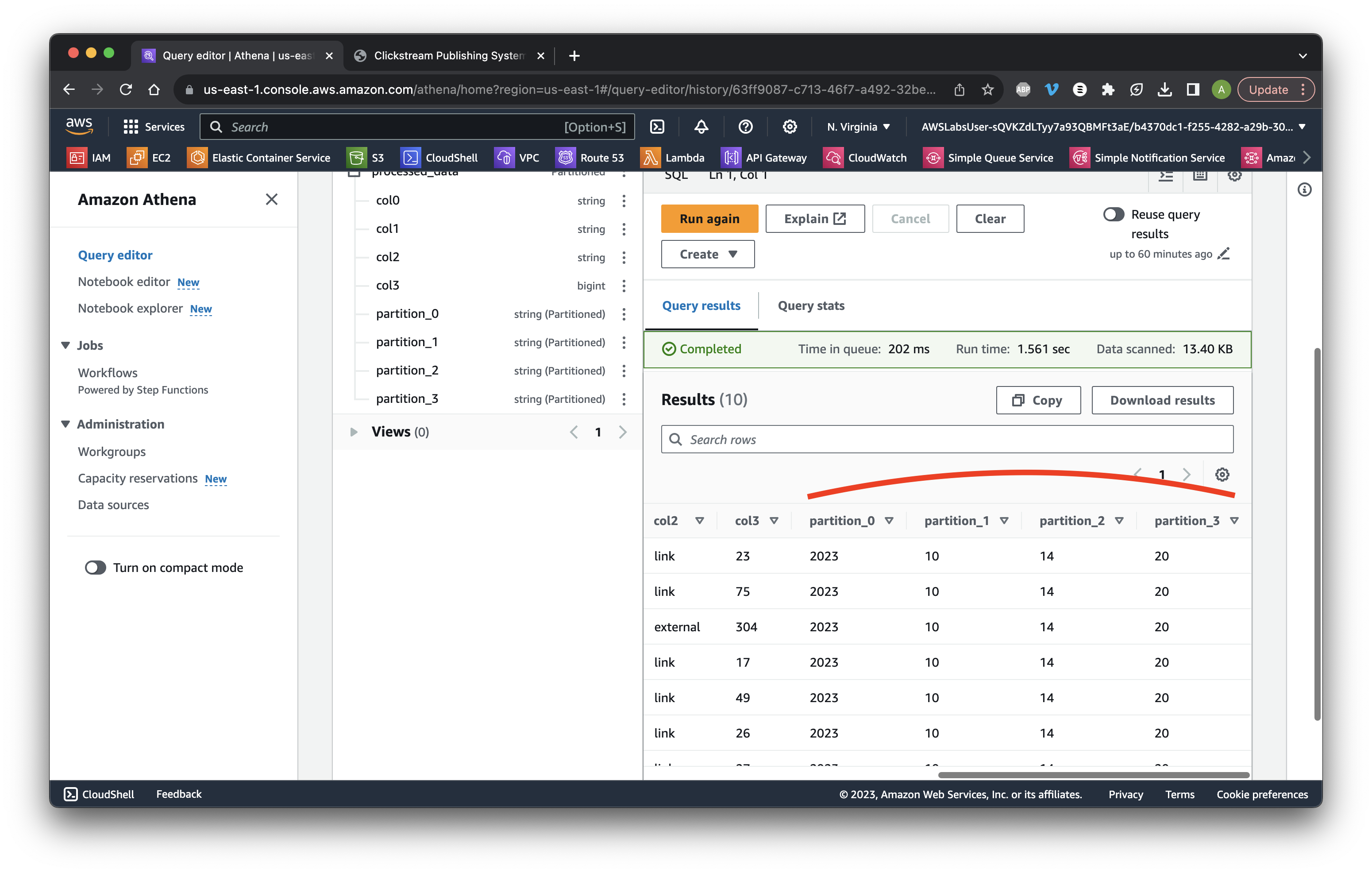
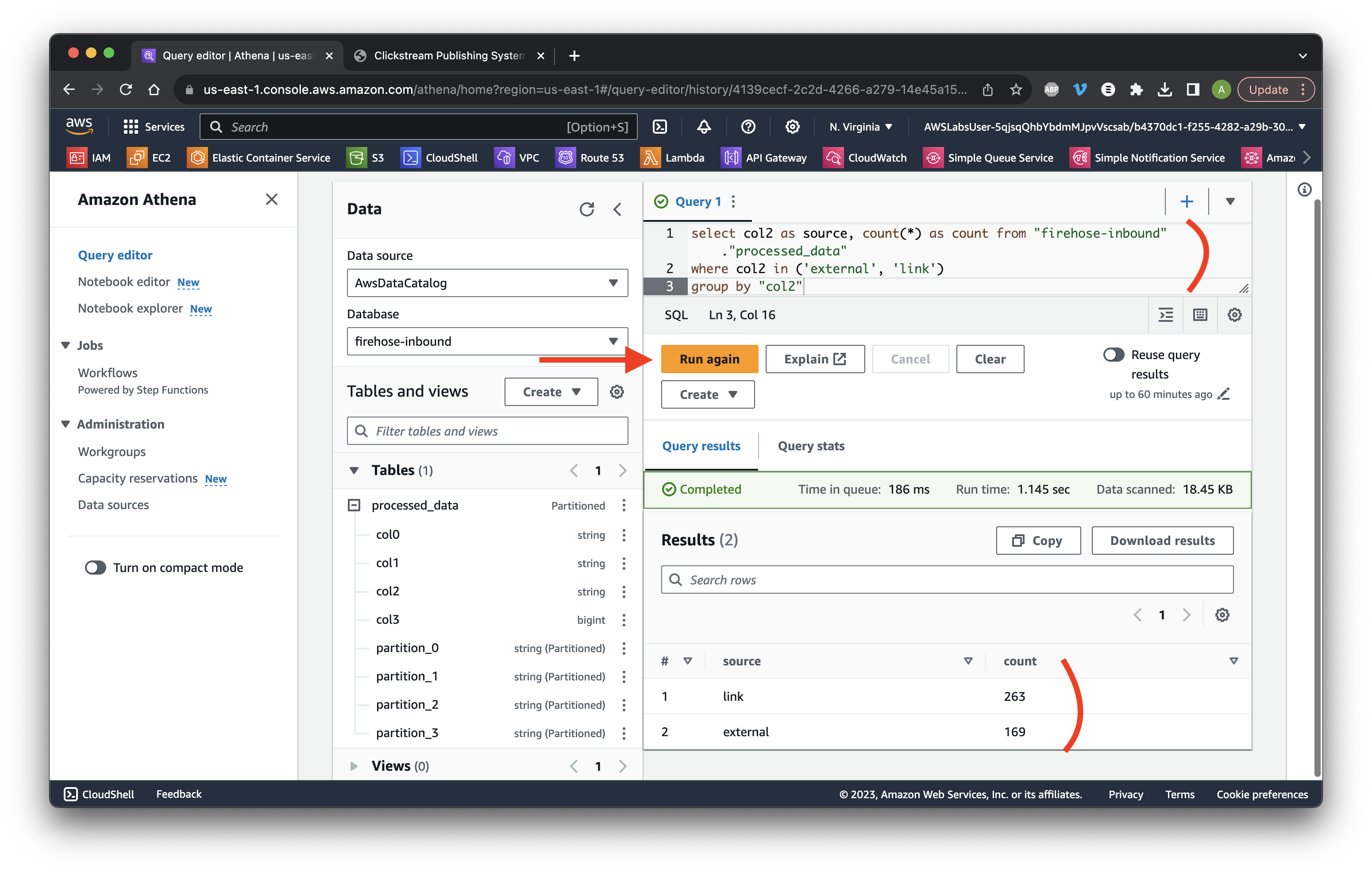
Scroll up to Query and type: select col2 as source, count(*) as count from "firehose-inbound"."processed_data" where col2 in ('external', 'link') group by "col2” then click Run again. Review the record counts.
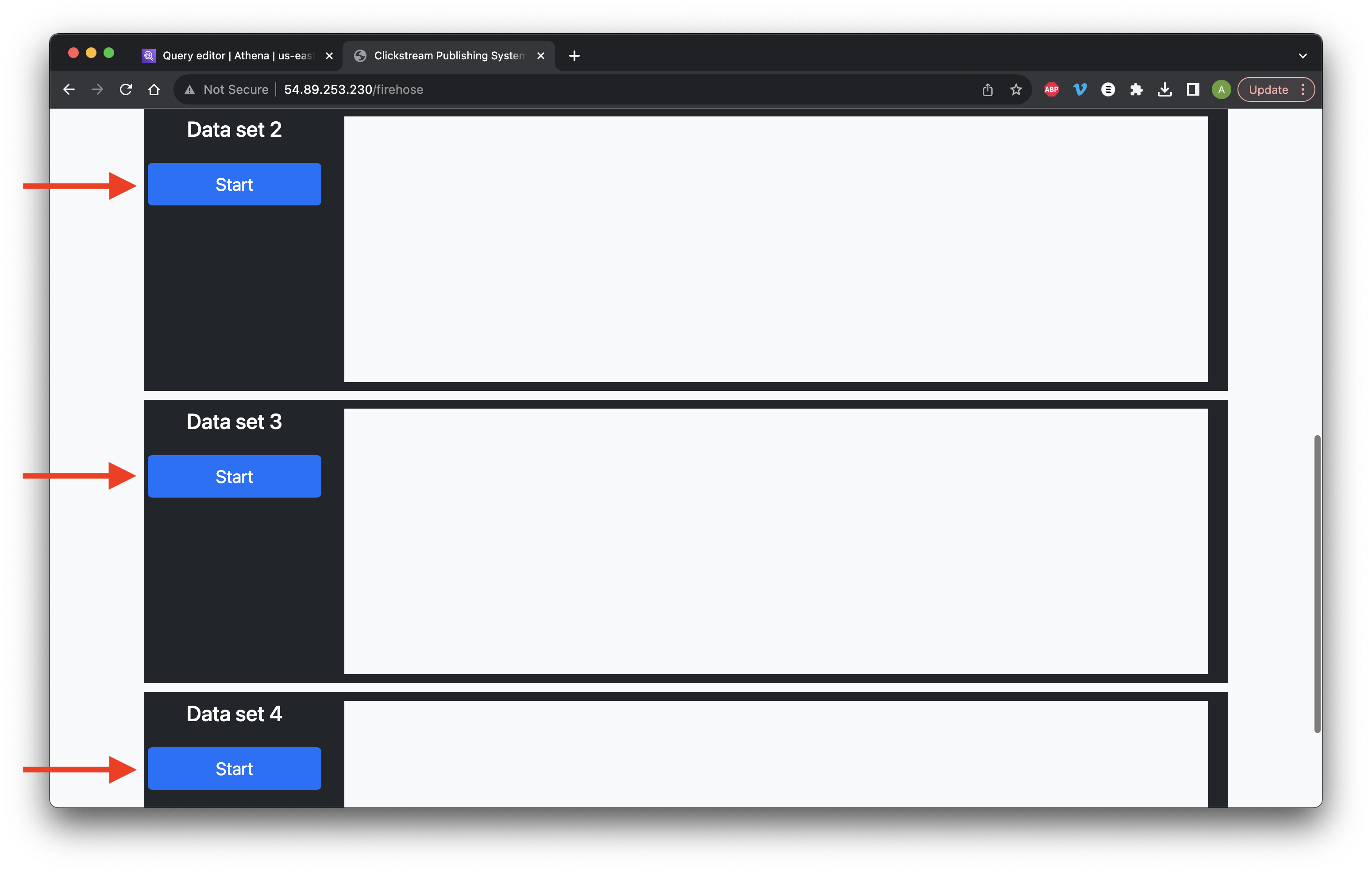
Return to the application in the other browser and click Start for Data set 2, 3, and 4.
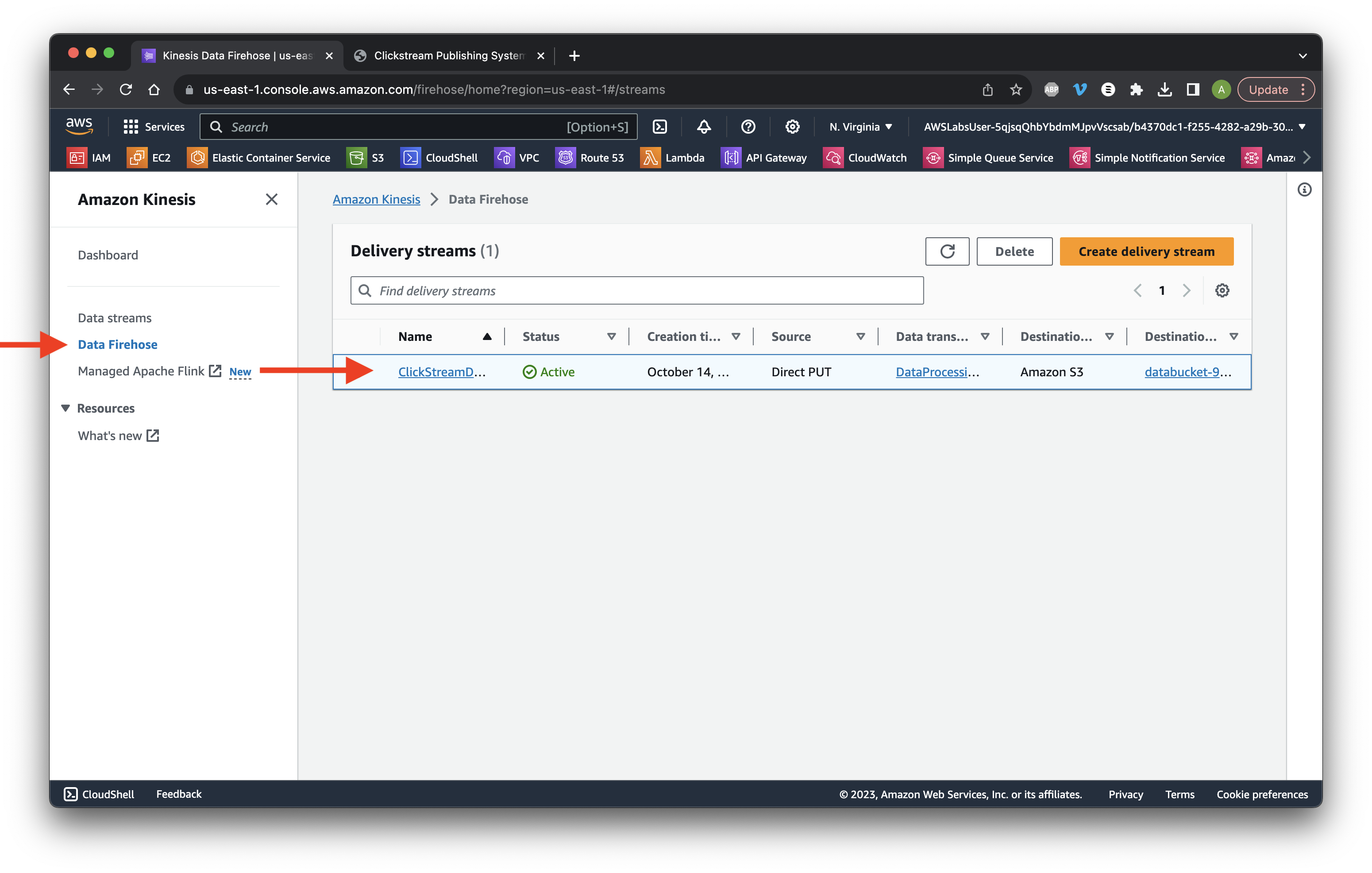
Return to Kinesis and go to Data Firehose. Click the name of our stream.
Scroll down and click the Configuration tab. Click Edit for Transform and convert records.
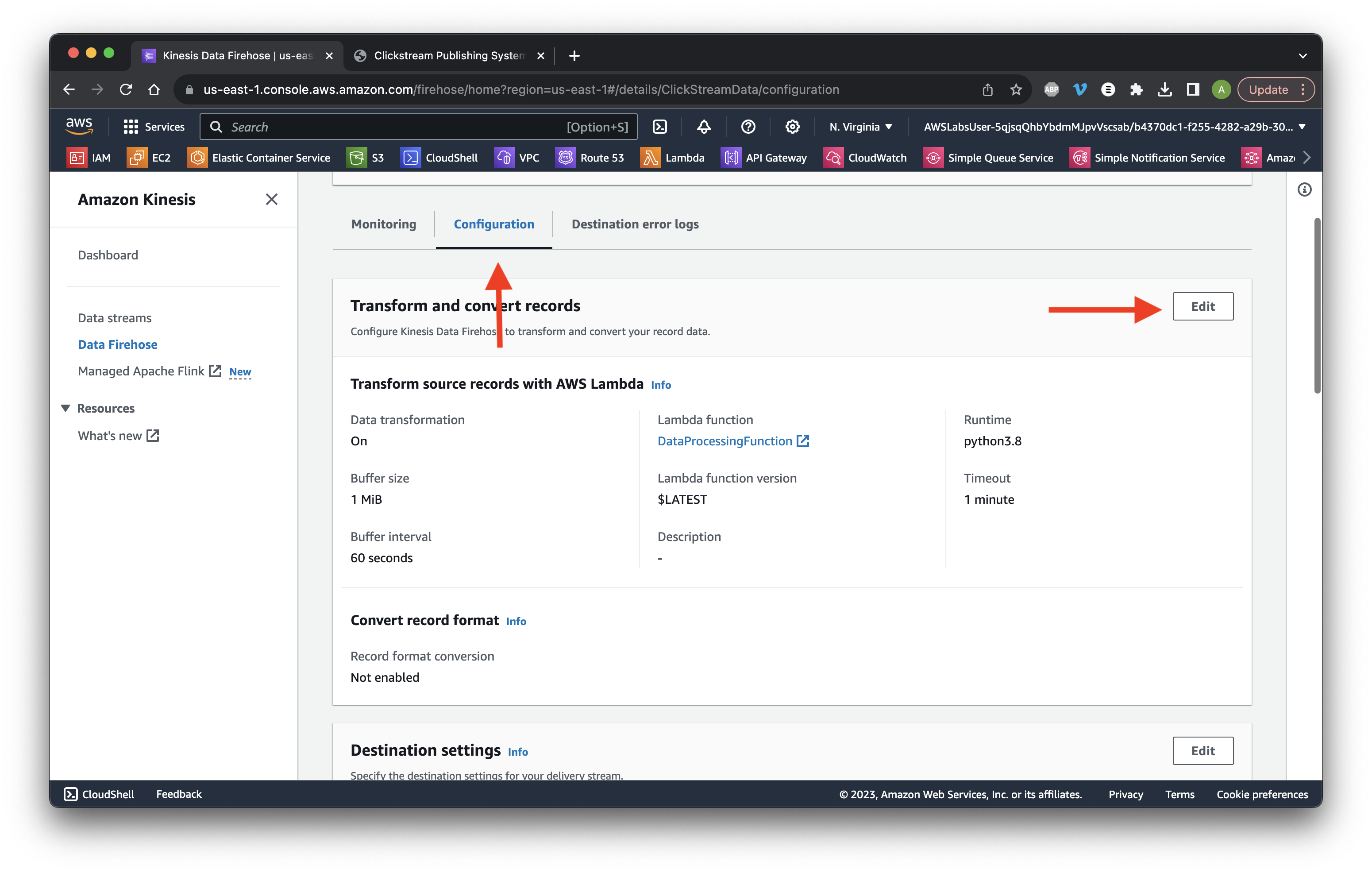
Click Browse and select AnalyticsDestinationFunction. Click Choose.
Scroll down and click Edit for the Destination settings.
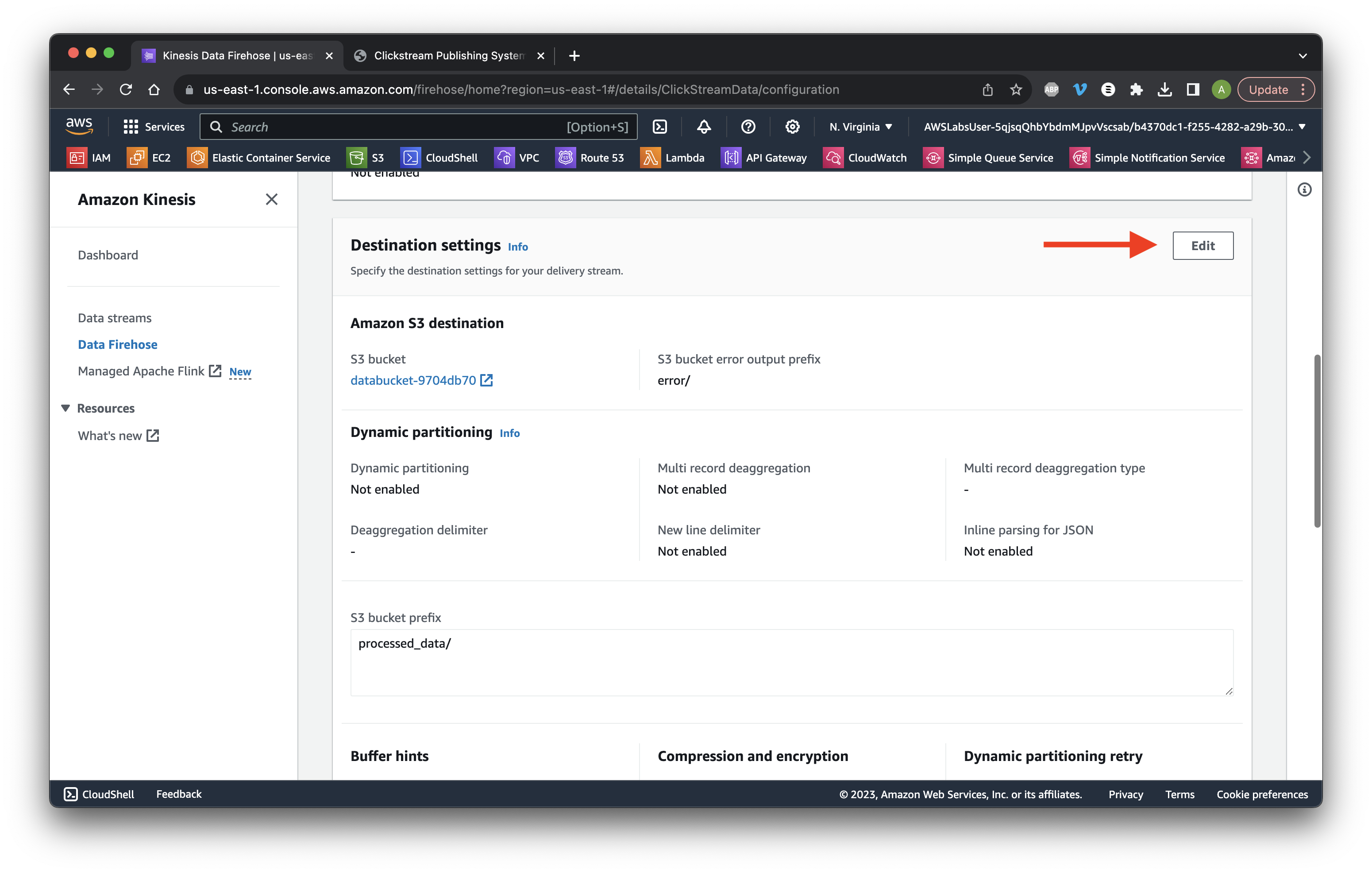
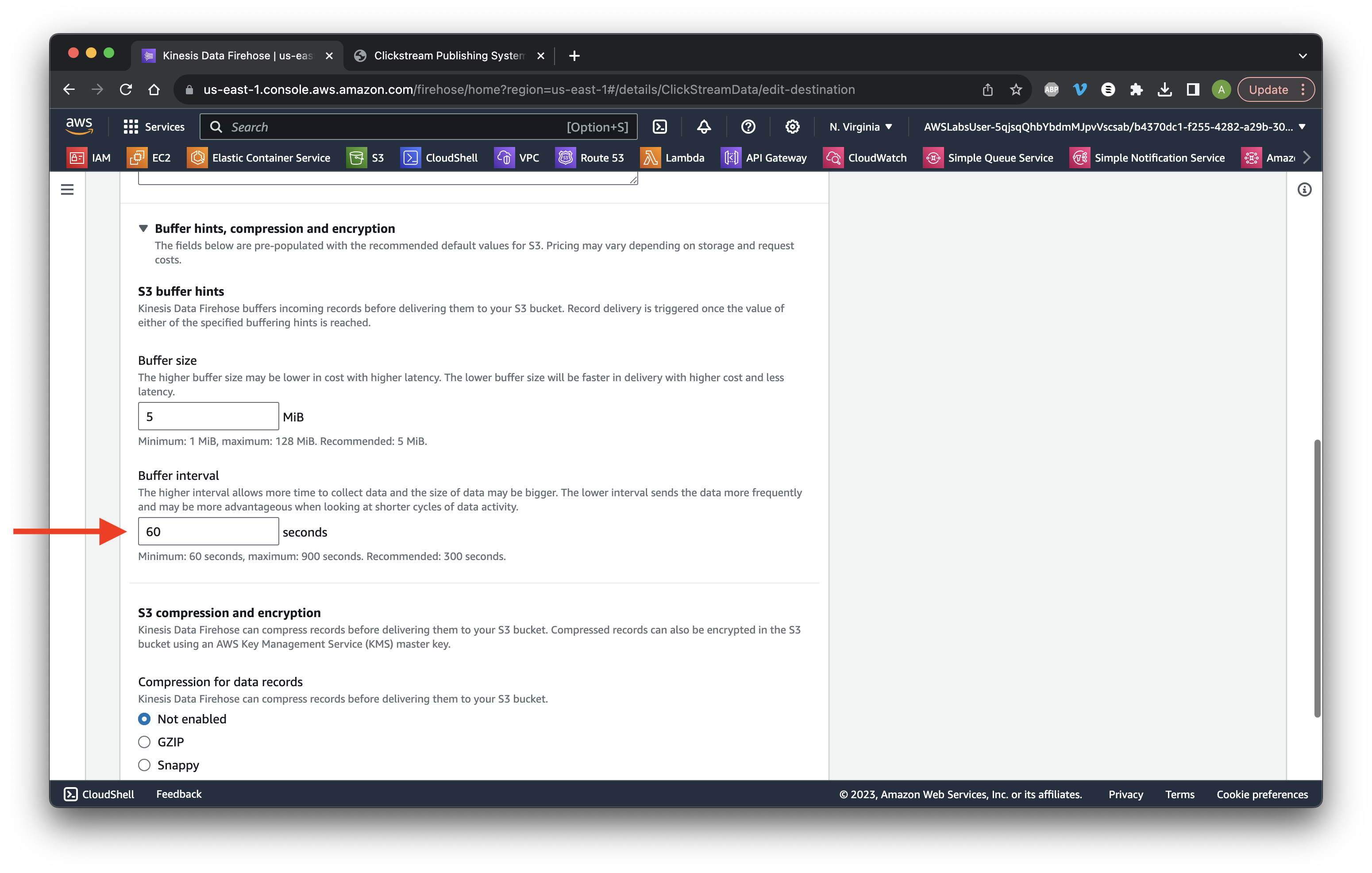
Scroll down to Buffer hints and change the interval to 60 seconds. Click Save changes. Success!